1. 项目概览
| 维度 | 信息 |
|---|---|
| 项目 | HKUDS/RAG-Anything |
| 定位 | All-in-One Multimodal Document Processing RAG system |
| 技术基础 | 基于 LightRAG,集成 MinerU / Docling / PaddleOCR 等解析能力 |
| 主要语言 | Python |
| 开源协议 | MIT |
| 创建时间 | 2025-06-06 |
| 最近推送 | 2026-06-15 |
| GitHub 热度 | 2026-06-30 查询:约 21.7k stars、2.5k forks、106 open issues |
| 包安装 | pip install raganything |
RAG-Anything 试图解决传统 RAG 的一个关键短板:现实企业文档通常不是单纯文本,而是混合了段落、图片、图表、表格、公式和复杂版式。传统“抽文本 -> 切 chunk -> 向量检索”的方案会丢失大量结构关系。RAG-Anything 则把文档拆成不同模态,并用多模态知识图谱和混合检索来组织这些内容。
官方架构示意图:
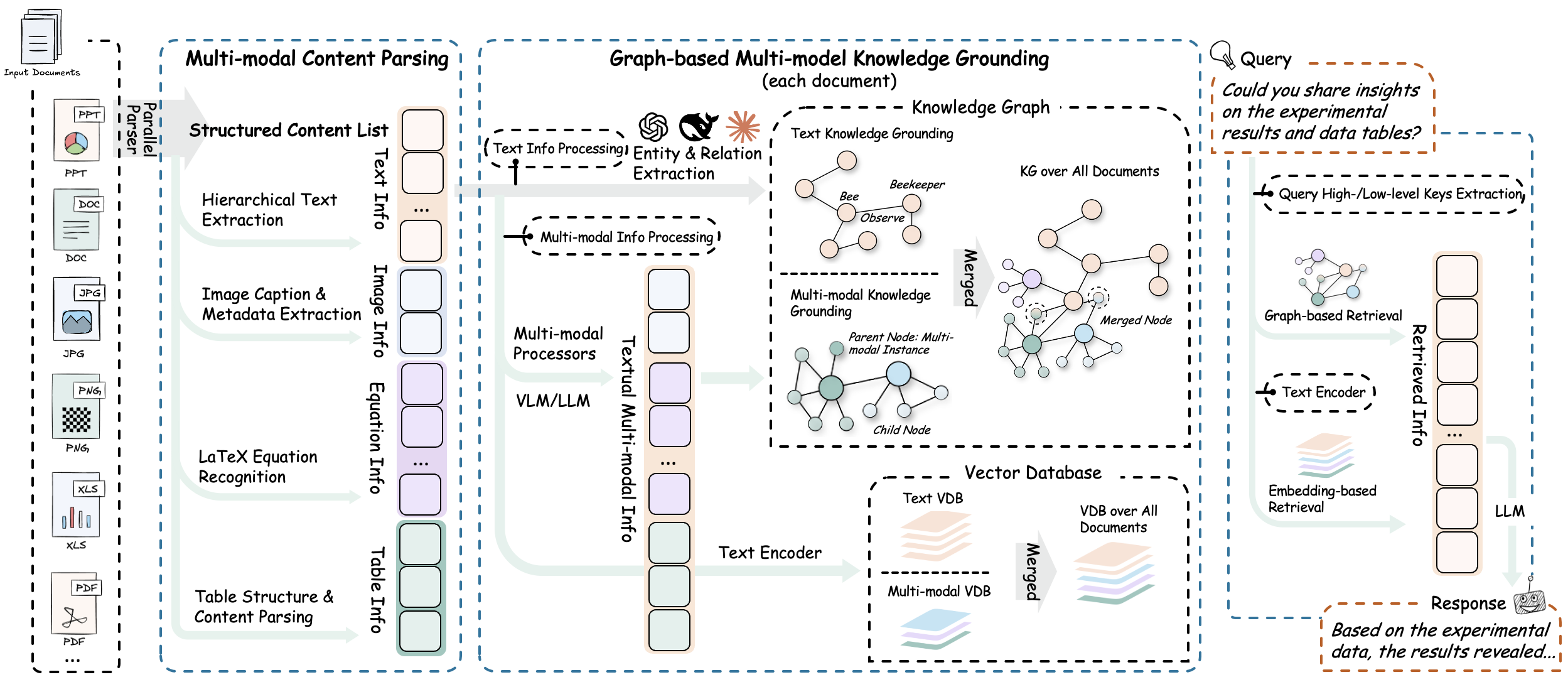
2. 它主要能做什么
| 能力 | 说明 | 对客户的价值 |
|---|---|---|
| 多格式文档解析 | 支持 PDF、Office、图片、文本等 | 企业历史资料不用先人工转成干净文本 |
| 多模态内容处理 | 分别处理文本、图片、表格、公式、通用内容 | 能回答图表、公式、表格里的信息 |
| 多模态知识图谱 | 抽取实体和跨模态关系,保留文档层级 | 比单纯向量库更能表达“图表属于哪个章节” |
| 混合检索 | 结合向量检索和图结构关系 | 对复杂问题更容易召回相关上下文 |
| 直接插入 content_list | 可接外部解析器产物,跳过内置解析 | 适合和客户现有 OCR/版面解析系统集成 |
| 可配置解析器 | MinerU、Docling、PaddleOCR 等 | 不同文档类型可选择更合适的解析路线 |
| VLM 增强查询 | 文档含图片时可引入视觉模型分析 | 适合图纸、截图、流程图、报表解读 |
3. 适用场景
| 场景 | 适配度 | 示例 |
|---|---|---|
| 企业复杂文档问答 | 高 | 产品手册、规章制度、投标文档、操作指南 |
| 金融/咨询报告分析 | 高 | 年报、研报、表格、图表、附录混合资料 |
| 科研论文助手 | 高 | 论文中的公式、实验表、图示、引用关系 |
| 工业知识库 | 中高 | 设备手册、维修图、流程图、参数表 |
| 法务/合同知识库 | 中 | 合同正文 + 附表 + 扫描件,需额外重视权限与准确率 |
| 单纯 FAQ 问答 | 中低 | 纯文本 FAQ 用普通 RAG 更轻量 |
售前上最好的切入话术是:“客户真正难的不是问答,而是把复杂文档可靠地变成可检索、可追溯、可引用的知识结构。”
4. 不太适合的场景
| 不适合点 | 原因 |
|---|---|
| 只处理纯文本 Markdown/FAQ | 普通 RAG 更简单、成本更低 |
| 对实时低延迟要求极高 | 多模态解析、VLM 分析、知识图谱构建会增加耗时 |
| 文档权限非常复杂但无权限体系 | 项目本身是框架,企业级权限隔离需要应用层补齐 |
| 对答案 100% 合规可审计 | 仍要做引用、人工复核、评测集和防幻觉策略 |
| 文档扫描质量极差 | OCR/版面分析质量会成为瓶颈 |
5. 架构与工作流
RAG-Anything 的典型链路可以概括为:
- 文档解析:使用 MinerU、Docling 或 PaddleOCR 等将 PDF/Office/图片拆解为结构化内容。
- 内容分类:把内容分为 text、image、table、equation、generic content 等类型。
- 模态处理:图片走视觉分析,表格走结构化解释,公式保留 LaTeX 和语义描述。
- 图谱构建:抽取实体,建立文本与图表、章节与元素、表格与指标之间的关系。
- 混合检索:查询时结合向量相似度和图关系,返回更完整的上下文。
- LLM 生成:用召回上下文生成答案,可结合多模态信息。
这套架构的售前亮点是:它不是简单把图片 OCR 成文字,而是试图保留“元素之间的关系”。对于客户的复杂文档,这个点非常关键。
6. 怎么用
安装:
pip install raganything
pip install 'raganything[all]'Office 文档需要额外安装 LibreOffice:
brew install --cask libreoffice源码安装:
git clone https://github.com/HKUDS/RAG-Anything.git
cd RAG-Anything
uv sync
uv run python examples/raganything_example.py --help最小使用思路:
from raganything import RAGAnything, RAGAnythingConfig
config = RAGAnythingConfig(
working_dir="./rag_storage",
parser="mineru",
parse_method="auto",
enable_image_processing=True,
enable_table_processing=True,
enable_equation_processing=True,
)官方示例需要配置 LLM、视觉模型和 embedding 函数,然后调用 process_document_complete 或直接插入 content_list。content_list 对系统集成很有价值,因为企业可以先用自己的 OCR/解析服务得到结构化内容,再交给 RAG-Anything 做多模态 RAG。
7. 售前可以怎么讲
一句话定位:
“RAG-Anything 是面向复杂企业文档的多模态 RAG 框架,能把 PDF、Office、图片、表格和公式统一纳入知识库检索与问答。”
价值映射:
| 客户痛点 | 讲法 |
|---|---|
| 文档里大量表格和图片,普通知识库答不出来 | RAG-Anything 将表格、图片、公式作为一等内容处理 |
| 传统 OCR 后结构丢失 | 它保留章节层级、元素关系和跨模态关联 |
| 多种文档格式混杂 | 支持 PDF、Office、图片、TXT/MD 等格式路线 |
| 已有文档解析系统 | 可通过 content_list 直接接入,不必完全推翻现有架构 |
| 希望提升问答可解释性 | 图谱和 page_idx 等元数据有助于引用原文位置 |
8. Demo/PoC 建议
建议用客户真实文档,而不是公开 demo 文档。PoC 分三类材料:
| 材料 | 测试问题 |
|---|---|
| 带图表的财报/研报 | “某指标趋势是什么?图中哪一年变化最大?” |
| 产品手册/设备手册 | “出现某错误码时该怎么处理?相关图示在哪页?” |
| 带公式论文/技术白皮书 | “公式中的变量含义是什么?实验表说明了什么?” |
PoC 指标:
| 指标 | 说明 |
|---|---|
| 解析成功率 | 文档是否能完整拆出文本、表格、图片、公式 |
| 图表问答准确率 | 针对图表/表格问题是否答对 |
| 引用可追溯性 | 是否能定位到页码、章节、元素 |
| 构建耗时 | 每百页文档解析 + 入库时间 |
| 查询延迟 | hybrid 查询平均响应时间 |
| 人工修正量 | 表格/公式/OCR 需要人工修正的比例 |
9. 常见客户问题
| 问题 | 回答建议 |
|---|---|
| 它和普通向量数据库有什么区别? | 向量数据库主要负责相似度检索;RAG-Anything 更关注复杂文档解析、多模态内容理解和图关系组织。 |
| 能处理扫描 PDF 吗? | 可通过 OCR 路线处理,但效果取决于扫描质量、语言、版式和解析器能力。 |
| 是否必须用 OpenAI? | 官方示例使用 OpenAI 风格函数,但框架可传入自定义 LLM、视觉模型和 embedding 函数。 |
| 能私有化部署吗? | 可以,但需要准备本地模型、OCR/解析环境、存储、队列、权限和服务化封装。 |
| 是否能保证答案不幻觉? | 不能仅靠框架保证。需要引用、置信度、评测集、拒答策略和人工复核流程。 |
10. 风险和注意事项
- 解析质量决定上限:复杂表格、跨页表、扫描件、手写内容会显著影响效果。
- 多模态成本较高:VLM 分析图片、图表可能带来额外费用和延迟。
- 工程集成仍需投入:权限、审计、租户隔离、增量更新、失败重试不是开箱即用的企业系统。
- 评测很关键:必须为客户业务构建标准问题集,否则很难判断是否真正比普通 RAG 好。
- 许可证较友好:MIT 对商业集成友好,但仍要确认所接模型、解析器和数据的授权。
11. 我的售前判断
RAG-Anything 是本批项目里非常值得售前长期关注的一个方向。它切中企业知识库的真实痛点:文档不是干净文本,而是复杂版式和多模态信息混在一起。普通 RAG 在这类场景下容易“看不到表格和图片”,RAG-Anything 的价值就在于提供了一条更完整的处理链。
建议把它用于“复杂文档智能问答”“多模态知识库”“研发/金融/制造文档助手”的方案讲解和 PoC。不要只演示纯文本问答,那样体现不出差异。真正能打动客户的是:拿一份带图表、公式和附录的真实文档,让系统回答普通 RAG 答不好的问题。
12. 参考资料
- GitHub: https://github.com/HKUDS/RAG-Anything
- 论文: https://arxiv.org/abs/2510.12323
- PyPI: https://pypi.org/project/raganything/
- LightRAG: https://github.com/HKUDS/LightRAG
- MinerU: https://github.com/opendatalab/MinerU