1. 一句话定位
Scrapling 是一个面向现代网站的数据采集框架。
它不是单纯的 HTML 解析库,也不是只会打开浏览器的自动化工具,而是把以下能力组合在一起:
- 高性能 HTML 解析和选择器。
- HTTP 请求、动态浏览器、隐身浏览器三类 Fetcher。
- 可持续运行的 Session。
- 面向大规模任务的 Spider 框架。
- 自适应元素定位,页面结构变化后仍尽量找回目标元素。
- 代理轮换、阻断检测、暂停恢复、开发缓存。
- CLI 和交互式 Web Scraping Shell。
- 面向 AI Agent 的 MCP Server。
售前可这样表达:
Scrapling 适合把“网页数据采集”从零散脚本升级成可维护的数据采集工程:简单页面走快速 HTTP,动态页面走浏览器,受保护页面走 stealth 模式,大规模任务走 Spider,并且可以通过 MCP 给 AI Agent 提供可控、低 token 的网页提取能力。
2. 它主要能做什么
2.1 快速页面抓取和解析
Scrapling 提供类似 Scrapy/Parsel、BeautifulSoup 的选择器体验,支持:
- CSS selector。
- XPath。
- BeautifulSoup 风格的
find_all。 - 文本搜索。
- 正则搜索。
- 链式选择器。
- 父级、子级、兄弟节点导航。
- 相似元素查找。
- 自动选择器生成。
典型示例:
from scrapling.fetchers import Fetcher, FetcherSession
with FetcherSession(impersonate='chrome') as session:
page = session.get('https://quotes.toscrape.com/', stealthy_headers=True)
quotes = page.css('.quote .text::text').getall()售前解读:
- 对静态页面和普通列表页,它可以作为比 Selenium/Playwright 更轻的采集方式。
- 对团队来说,API 比裸
requests + lxml更完整,维护成本更低。
2.2 自适应元素定位
Scrapling 的 README 强调 parser 能从网站变化中学习,当页面更新后自动重新定位元素。典型写法:
from scrapling.fetchers import StealthyFetcher
StealthyFetcher.adaptive = True
p = StealthyFetcher.fetch('https://example.com', headless=True, network_idle=True)
products = p.css('.product', auto_save=True)
products = p.css('.product', adaptive=True)这对业务很重要,因为网页采集最大的维护成本之一就是页面改版:
- class 名变化。
- DOM 层级变化。
- 列表结构轻微调整。
- 商品卡片样式更新。
Scrapling 不能保证所有改版都自动修复,但它试图降低选择器脆弱性,适合售前讲“减少采集脚本维护成本”。
2.3 三类 Fetcher 覆盖不同网站
官方文档把 Fetcher 分成三类:
| Fetcher | 适合场景 | 特点 | 售前理解 |
|---|---|---|---|
Fetcher | 普通静态页面、HTTP 请求即可完成的页面 | 速度最快、资源占用低、可模拟浏览器 TLS/headers、支持 HTTP/3 | 优先选择,成本最低 |
DynamicFetcher | JS 动态加载、SPA、小型自动化、中等保护 | 使用 Playwright Chromium/Chrome | 页面需要执行 JS 时使用 |
StealthyFetcher | 动态页面、反爬保护、Cloudflare Turnstile/Interstitial 等 | 隐身浏览器、指纹伪装、反机器人绕过能力更强 | 成本更高,但适合复杂站点 |
售前建议:
不要一上来就用最重的浏览器和 stealth 模式。采集方案应先分层:普通请求优先,动态页面再用浏览器,确有保护再用 StealthyFetcher。这样能控制成本、速度和稳定性。
2.4 Spider 大规模爬取框架
Scrapling 的 Spider 系统类似 Scrapy,但整合了自身 parser 和 fetcher,支持:
start_urls。- async
parsecallback。 Request/Response对象。- 并发爬取。
- 按域名节流和下载延迟。
- 多 Session。
- 请求优先级队列。
- URL 去重。
- blocked request 检测与重试。
- robots.txt 可选遵守。
- checkpoint 暂停/恢复。
- streaming 输出。
- 开发模式缓存响应。
- JSON/JSONL 导出。
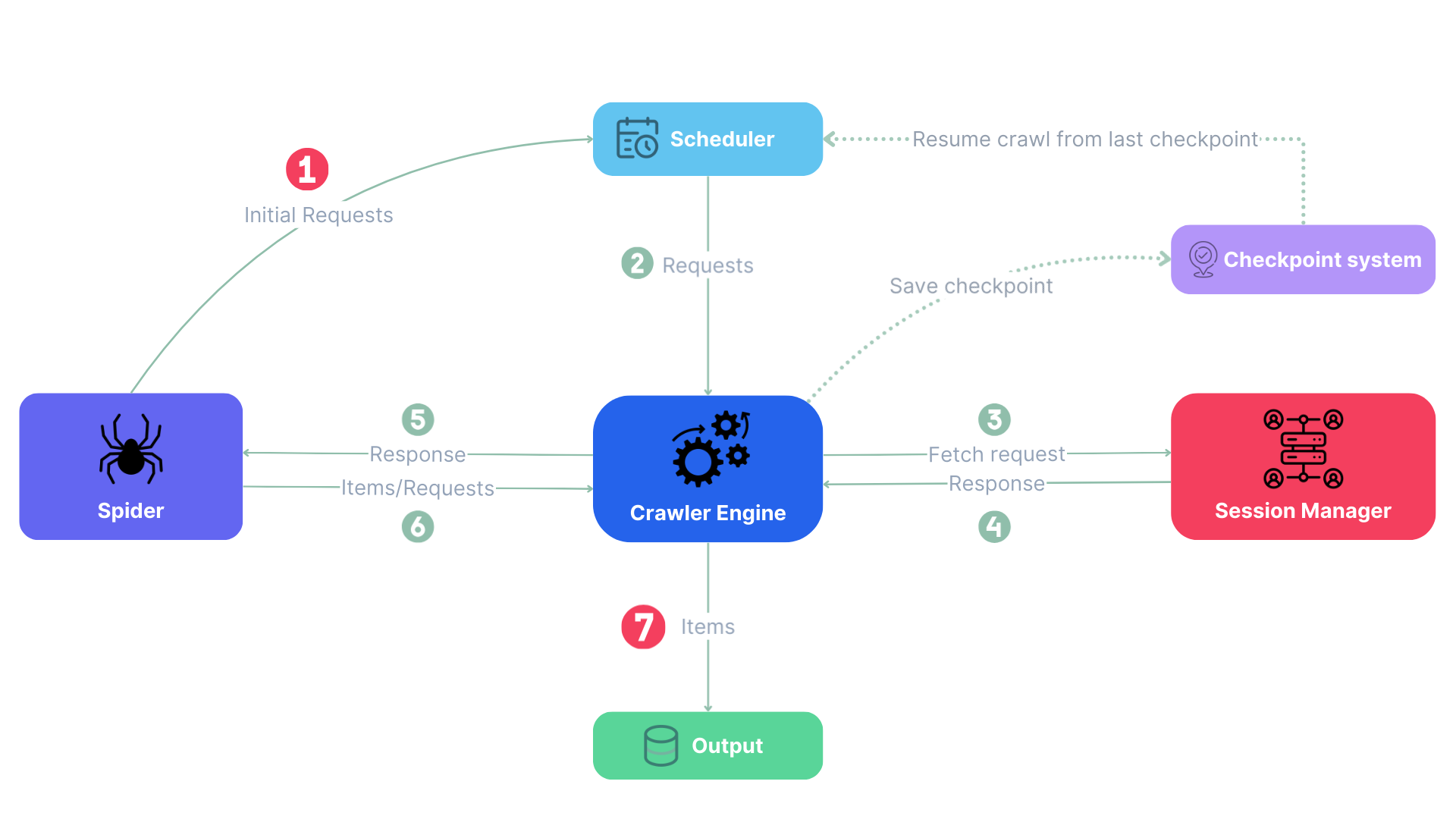
官方 Spider 数据流可以理解为:
- Spider 产生初始请求。
- Scheduler 进入优先级队列并做 fingerprint 去重。
- Crawler Engine 根据并发、域名限制、下载延迟、robots.txt 规则取请求。
- Session Manager 根据
sid选择 HTTP、Dynamic 或 Stealthy Session。 - Session 抓取页面并返回 Response。
- callback 产出 item 或后续 Request。
- 如设置
crawldir,系统会保存 checkpoint,后续可恢复。
2.5 MCP Server 给 AI Agent 使用
Scrapling 的 MCP Server 是它区别于传统爬虫库的重要亮点。它能把 Scrapling 的采集能力直接暴露给 Claude、Cursor、Claude Code 等支持 MCP 的 Agent。
官方 MCP Server 提供 10 类工具:
| 工具 | 用途 |
|---|---|
get | 快速 HTTP 抓取,支持浏览器指纹模拟 |
bulk_get | 多 URL 并发 HTTP 抓取 |
fetch | Chromium/Chrome 动态内容抓取 |
bulk_fetch | 多页面浏览器并发抓取 |
stealthy_fetch | 隐身浏览器抓取,处理 Cloudflare 等保护 |
bulk_stealthy_fetch | 多 URL stealth 并发抓取 |
screenshot | 对已打开浏览器 Session 截图,返回模型可见的图片内容 |
open_session | 创建持久浏览器 Session |
close_session | 关闭 Session |
list_sessions | 查看活动 Session |
官方文档强调一个重要价值:Scrapling MCP 允许先用 CSS selector 缩小内容范围,再把内容交给 AI,从而减少无关内容进入上下文,节省 token。
这点很适合售前讲 AI Agent 场景:
很多网页提取工具会把整页内容塞给大模型,再让模型找字段。Scrapling MCP 可以先在工具层用选择器提取目标区域,再交给模型理解,速度更快、token 更少、受页面噪声影响更小。
2.6 CLI 和交互式 Shell
Scrapling 也可以直接从终端使用:
scrapling shell
scrapling extract get 'https://example.com' content.md
scrapling extract get 'https://example.com' content.txt --css-selector '#fromSkipToProducts' --impersonate 'chrome'
scrapling extract fetch 'https://example.com' content.md --css-selector '#fromSkipToProducts' --no-headless
scrapling extract stealthy-fetch 'https://nopecha.com/demo/cloudflare' captchas.html --css-selector '#padded_content a' --solve-cloudflare这对售前 PoC 很有用,因为不用先写完整工程,就能演示:
- ���网页抽正文为 Markdown。
- 抽某个 CSS selector 的内容。
- 对动态网页用浏览器方式提取。
- 对受保护页面用 stealth 模式验证可行性。
3. 适用场景
3.1 公开数据采集和数据管道
适合:
- 新闻、公告、招投标、政策网页采集。
- 品牌官网、产品页、文档页定期抓取。
- 行业情报和公开网页归档。
- 数据湖/知识库的网页数据入口。
售前价值:
- 比手写脚本更标准化。
- 比浏览器自动化更轻。
- 支持从单页到爬虫框架的渐进式扩展。
3.2 价格监控和竞品情报
适合:
- 电商商品标题、价格、库存、评价数据采集。
- 竞品官网活动页监控。
- 酒店、机票、票务、SaaS 定价页变化跟踪。
为什么适合:
- 自适应选择器可降低页面改版后的维护成本。
- 多 Session 和代理轮换适合中等规模抓取。
- Spider 支持 checkpoint 和 streaming,适合长任务。
售前提醒:
- 这类场景容易触及服务条款、频率限制和商业数据合规,要明确只采集允许采集的数据,并控制请求频率。
3.3 SEO、舆情和内容监测
适合:
- 搜索结果页或公开网页内容抽取。
- 品牌提及监测。
- 站点结构、标题、正文、链接检查。
- 内容变更监控。
Scrapling 的 CLI 和 Markdown 输出,对构建内容监测流水线很方便。
3.4 AI Agent 网页提取工具
适合:
- 给企业 Agent 平台补一个网页读取/提取 MCP 工具。
- 让 Agent 按指定 selector 抽商品、文章、列表。
- 对动态网页和复杂页面做会话式分析。
- 让 Agent 截图并结合视觉理解。
为什么有价值:
- MCP Server 内置工具,接入成本低。
- 支持 bulk 工具,避免 Agent 一个 URL 一个 URL 慢慢抓。
- 支持 session 复用,减少重复打开浏览器。
- 支持 prompt injection 清理,默认
main_content_only时会移除隐藏元素、HTML 注释、零宽字符等潜在注入内容。
3.5 采集脚本研发和调试
适合数据工程师和爬虫工程师:
- 用交互式 Shell 快速试 selector。
- 把 curl 请求转换成 Scrapling 请求。
- 开发模式缓存响应,避免调试时反复打目标网站。
- 用浏览器打开请求结果,快速确认页面状态。
4. 不太适合的场景
| 不适合场景 | 原因 | 建议 |
|---|---|---|
| 未获授权的敏感数据采集 | README 明确要求遵守法律、隐私、ToS 和 robots.txt | 必须先做合规评估 |
| 极大规模商业爬虫平台 | Scrapling 是框架,不是完整分布式调度平台 | 需要配合队列、任务调度、代理池、监控、存储系统 |
| 只需要解析本地 HTML | 直接用 lxml、BeautifulSoup、Parsel 可能更轻 | 小任务不必引入完整 fetcher/spider |
| 强验证码/登录/风控链路 | StealthyFetcher 有能力,但不等于无限绕过所有保护 | 需要人工验证、代理服务和合法授权 |
| 对采集合法性边界不清楚的客户 | 数据合规风险高 | 先做法律和业务边界确认 |
5. 架构和核心能力
5.1 能力分层
HTTP / Dynamic / Stealthy"] Fetcher --> Parser["Parser / Selector
CSS / XPath / Text / Similarity"] Parser --> Spider["Spider Framework
Scheduler / Engine / Session Manager"] Spider --> Output["Items / JSON / JSONL / Markdown / HTML"] Spider --> Ops["Proxy / Checkpoint / Cache / Stats / Retry"]
5.2 和 Scrapy 的关系
Scrapling 的 Spider 借鉴 Scrapy,但做了现代化取舍:
| 概念 | Scrapy | Scrapling |
|---|---|---|
| Spider | scrapy.Spider | scrapling.spiders.Spider |
| Callback | 同步 parse 为主 | async parse |
| Downloader | Downloader + Middlewares | Session Manager,多种 Session |
| Pause/Resume | JOBDIR | crawldir |
| Export | Feed exports | to_json() / to_jsonl() 或 hooks |
| Streaming | 非核心能力 | async for item in spider.stream() |
| 多 Session | 需要自定义 | 原生支持不同 session ID 路由 |
| blocked 检测 | 自定义中间件 | 内置 is_blocked() 和 retry hook |
售前判断:
- 如果客户已有成熟 Scrapy 体系,不一定要替换。
- 如果客户要从新项目开始,且同时需要动态网页、stealth、MCP、AI Agent 接入,Scrapling 会更一体化。
6. 怎么用
6.1 安装
基础安装只包含 parser engine:
pip install scrapling如果要使用 fetchers / spiders:
pip install "scrapling[fetchers]"
scrapling install如果要使用 MCP:
pip install "scrapling[ai]"
scrapling install
scrapling mcp如果要使用 Shell 和 extract 命令:
pip install "scrapling[shell]"全部安装:
pip install "scrapling[all]"
scrapling installDocker:
docker pull pyd4vinci/scrapling
docker pull ghcr.io/d4vinci/scrapling:latest6.2 Spider 示例
from scrapling.spiders import Spider, Request, Response
class QuotesSpider(Spider):
name = "quotes"
start_urls = ["https://quotes.toscrape.com/"]
concurrent_requests = 10
async def parse(self, response: Response):
for quote in response.css('.quote'):
yield {
"text": quote.css('.text::text').get(),
"author": quote.css('.author::text').get(),
}
next_page = response.css('.next a')
if next_page:
yield response.follow(next_page[0].attrib['href'])
result = QuotesSpider().start()
result.items.to_json("quotes.json")6.3 多 Session 示例
from scrapling.spiders import Spider, Request, Response
from scrapling.fetchers import FetcherSession, AsyncStealthySession
class MultiSessionSpider(Spider):
name = "multi"
start_urls = ["https://example.com/"]
def configure_sessions(self, manager):
manager.add("fast", FetcherSession(impersonate="chrome"))
manager.add("stealth", AsyncStealthySession(headless=True), lazy=True)
async def parse(self, response: Response):
for link in response.css('a::attr(href)').getall():
if "protected" in link:
yield Request(link, sid="stealth")
else:
yield Request(link, sid="fast", callback=self.parse)6.4 MCP Server 配置示例
Claude Desktop 配置示例:
{
"mcpServers": {
"ScraplingServer": {
"command": "scrapling",
"args": ["mcp"]
}
}
}HTTP transport:
scrapling mcp --http --host '127.0.0.1' --port 80007. 售前可以怎么讲
7.1 面向业务方
Scrapling 可以帮助我们把公开网页数据稳定接入业务系统,例如价格监控、竞品跟踪、公告采集、内容监测。它比一次性脚本更可维护,比纯浏览器自动化更轻,并且能处理动态页面和部分反爬场景。
7.2 面向技术负责人
它的优势是分层清晰:普通页面用轻量 HTTP,动态页面用浏览器,复杂保护页面用 stealth,规模化任务用 Spider,多 URL 用 bulk/session,Agent 场景用 MCP。这样可以按场景选择成本最低但足够稳定的抓取路径。
7.3 面向 AI Agent 平台负责人
Scrapling MCP 的亮点是工具层先提取目标元素,再交给模型处理,避免把整页无关内容塞进上下文。对于网页读取、产品信息抽取、竞品页分析、知识库采集,这比普通网页读取工具更可控,也更省 token。
8. 常见客户问题
| 客户问题 | 回答建议 |
|---|---|
| 它和 Scrapy 有什么区别? | Scrapy 是成熟爬虫框架;Scrapling 更强调现代网页、动态页面、stealth fetcher、adaptive selector、MCP 和 AI Agent 集成。已有 Scrapy 体系不一定替换,新项目可以评估 Scrapling。 |
| 它能绕过反爬吗? | 它提供 StealthyFetcher、指纹伪装、Cloudflare Turnstile/Interstitial 相关能力,但不是万能绕过器。必须合法授权、控制频率,并根据目标站点验证。 |
| 能不能直接给 Agent 用? | 可以,Scrapling 提供 MCP Server,支持 get/fetch/stealthy_fetch/bulk/session/screenshot 等工具。 |
| 会不会很重? | 基础 parser 很轻;fetchers、browser、MCP、Shell 是可选依赖。可以按场景安装。 |
| 能不能做大规模采集? | Spider 支持并发、多 session、checkpoint、streaming、代理轮换,但完整大规模平台还需要调度、队列、存储、监控和代理池。 |
| 网站改版后能不能自动恢复? | 自适应选择器能降低维护成本,但不能保证所有改版都无感恢复。关键采集任务仍要有监控和异常告警。 |
| 是否合规? | 工具本身中立;项目 README 明确要求遵守法律、隐私、服务条款和 robots.txt。商用前要做合规边界确认。 |
9. PoC 建议
9.1 PoC 选题
建议选择一个合法、边界清晰、能衡量价值的场景:
- 抓取 100 个公开商品页的标题、价格、库存。
- 监控 20 个竞品定价页变化。
- 抓取一批公开公告并转成 Markdown。
- 给企业 Agent 接一个网页提取 MCP,比较 token 消耗。
- 对一个动态网页做普通 HTTP、DynamicFetcher、StealthyFetcher 分层对比。
9.2 PoC 验收指标
| 指标 | 说明 |
|---|---|
| 采集成功率 | 多次运行是否稳定拿到字段 |
| 字段准确率 | 标题、价格、日期等是否抽对 |
| 结构变化恢复率 | 页面 class/层级轻微变化后是否仍能抽取 |
| 速度 | 单页耗时、批量耗时、并发吞吐 |
| 资源占用 | 普通请求 vs 浏览器请求的 CPU/内存 |
| 阻断率 | 被目标站拦截/验证码/403 的比例 |
| 合规可控性 | robots.txt、频率、数据范围、日志是否明确 |
| Agent token 成本 | MCP selector 提取前后 token 消耗差异 |
9.3 演示脚本
- 用
Fetcher抓一个普通页面。 - 用 CSS selector 抽字段。
- 用
DynamicFetcher抓一个 JS 页面。 - 用
Spider做多页抓取并导出 JSON。 - 用 CLI 把页面转 Markdown。
- 用 MCP 让 Agent 按 selector 抽指定字段。
- 展示合规设置:频率限制、robots.txt、请求日志、数据字段白名单。
10. 风险和注意事项
10.1 合规风险是第一位
Scrapling README 的免责声明明确强调:
- 用于教育和研究。
- 使用者应遵守本地和国际数据抓取与隐私法律。
- 尊重网站服务条款和 robots.txt。
- 作者不对滥用负责。
售前中必须把这点放前面,不应把项目包装成“无限抓取任何网站”的工具。
10.2 反爬能力不等于可商用授权
即便技术上能访问,也不代表商业上可以采集。客户需要确认:
- 数据是否公开。
- 是否有授权。
- 是否允许商业使用。
- 是否涉及个人信息。
- 是否有频率限制。
- 是否需要停止机制。
10.3 Stealth 和浏览器模式成本较高
浏览器模式比普通 HTTP 更慢、更耗内存;stealth 模式又更重。大规模任务要做分层:
- 先普通请求。
- 不行再 dynamic。
- 仍不行再 stealth。
- 需要多站点多地区时再引入代理池和调度。
10.4 MCP Session 要注意资源释放
官方文档提醒:持久 Session 用完要关闭,否则浏览器会一直开着。Agent 工作流需要加入 close_session 和异常兜底。
11. 我的售前判断
Scrapling 是一个很适合“数据采集 + AI Agent”交叉场景的项目。
它的优势不是某个单点功能,而是组合完整:
- 轻量 HTTP。
- 动态浏览器。
- Stealth 模式。
- 自适应选择器。
- Spider 并发框架。
- CLI。
- MCP。
- Docker。
从售前角度,推荐的定位是:
面向现代网页的自适应数据采集框架,适合构建合法公开数据采集、竞品监控、AI Agent 网页提取和采集脚本工程化平台。
不建议的定位是:
“万能反爬绕过工具”或“任何网站都能抓”的承诺。
最适合推进的客户:
- 有公开网页数据采集需求,但当前脚本维护成本高。
- 正在做企业知识库/数据湖,需要网页数据入口。
- 做 AI Agent,需要可控网页提取工具。
- 做价格/竞品/SEO/内容监控。
- 有 Python 数据工程能力,希望自建而非完全采购 SaaS。
12. 参考资料
- GitHub 仓库:D4Vinci/Scrapling
- 官方 README:README.md
- 中文 README:README_CN.md
- 官方文档:Scrapling Docs
- Fetcher 选择:Fetchers basics
- Spider 架构:Spiders architecture
- MCP Server:Scrapling MCP Server Guide
- Spider 架构图:spider_architecture.png
- Cover 图:cover_light.svg
信息核查日期:2026-06-30。由于 GitHub API 匿名访问触发限流,本笔记未写入实时 stars/forks;项目能力、安装方式、基准、MCP 工具和合规提醒主要基于官方 README、中文 README 与 ReadTheDocs 文档整理。