best_skill.md。它适合用于 Agent 能力沉淀、提示词/技能工程自动优化、可评测任务的持续改进和研发型 PoC;但它不是开箱即用的企业 Agent 平台,对数据集、评分器、模型 API、运行成本和工程集成都有要求。1. 项目概览
| 项目 | 信息 |
|---|---|
| GitHub | microsoft/SkillOpt |
| 项目页 | https://microsoft.github.io/SkillOpt/ |
| 论文 | arXiv:2605.23904 |
| PyPI | skillopt |
| 项目定位 | 用深度学习式训练循环优化自然语言 Agent skills |
| 开源协议 | MIT |
| 主要语言 | Python |
| Python 要求 | Python >= 3.10 |
| 最新 PyPI 版本 | 0.1.0,检查日期:2026-06-27 |
| 最新 GitHub Release | v0.1.0,发布于 2026-06-02,检查日期:2026-06-27 |
| GitHub 热度 | 约 9.5k stars、903 forks、12 open issues,检查日期:2026-06-27 |
| 主要主题 | agent-skills、self-evolving-agents |
| 核心产物 | 训练后可部署的 Markdown 技能文档 best_skill.md |
2. 关键示意图
项目页首屏
项目页将 SkillOpt 定位为“text-space optimization for frozen agents”:冻结目标模型,不改模型权重,只优化自然语言技能文档。
方法总览
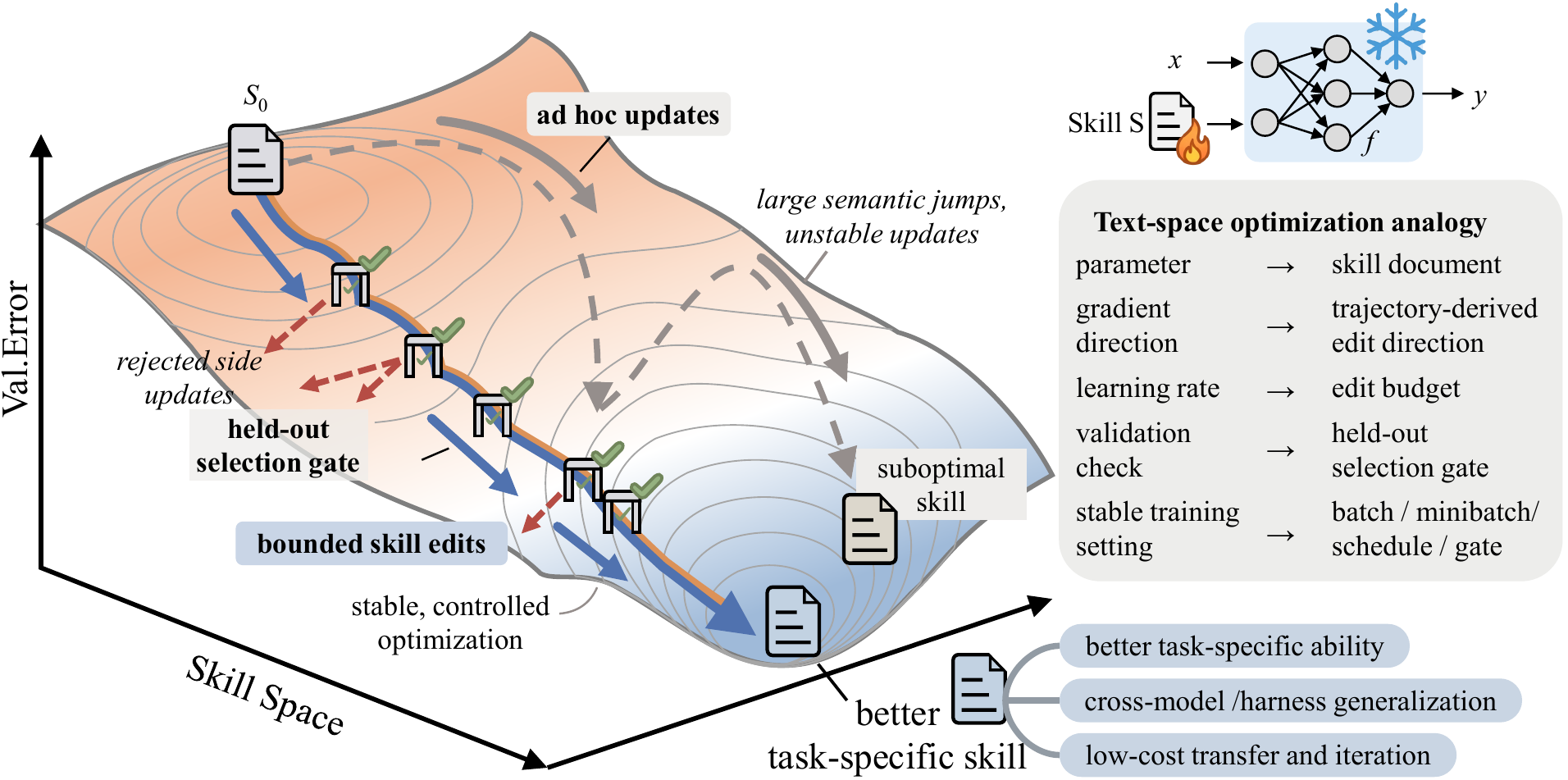
这张图适合用于对业务方解释:SkillOpt 不是在训练大模型,而是在训练“给 Agent 使用的技能说明书”。最终交付物是一个短小、可迁移、可版本化的 skill 文档。
训练流水线
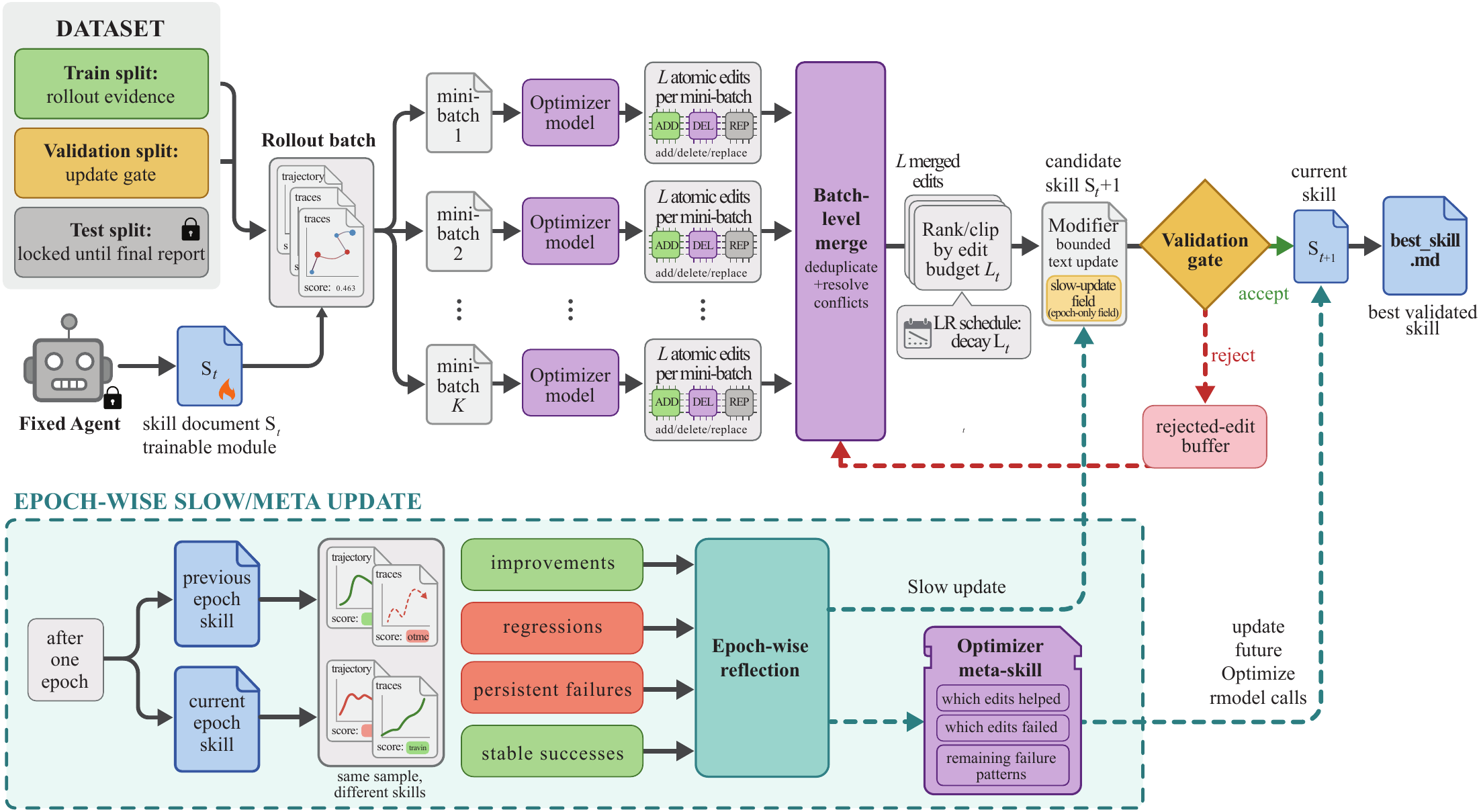
这张 pipeline 图是售前/方案交流里最关键的图。它展示了 SkillOpt 的基本闭环:固定 Agent + 当前 skill 文档 → 在训练集 rollout → 优化器模型根据轨迹提出 add/delete/replace 编辑 → 合并和裁剪编辑 → 生成候选 skill → 经过验证集 gate → 接受或拒绝 → 产出 best_skill.md。
训练趋势
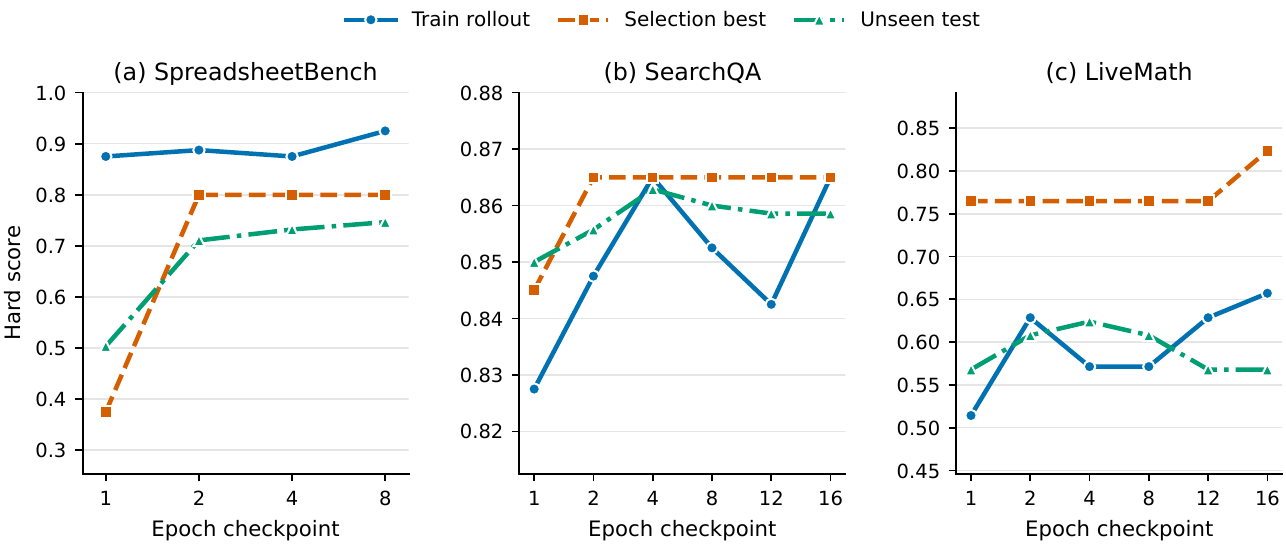
趋势图适合说明 SkillOpt 的“持续优化”思路:不是一次性写提示词,而是把任务表现、失败样本、验证集表现纳入长期迭代。
3. 它到底是什么
SkillOpt 可以理解为一个“Agent 技能训练框架”,但这里的“训练”不是训练模型参数,而是训练自然语言技能文档。
传统 Agent 技能或提示词通常有几种来源:
| 方式 | 问题 |
|---|---|
| 人工编写 | 依赖专家经验,迭代慢,难以系统复盘失败样本 |
| 强模型一次性生成 | 初稿快,但不一定能在真实任务上持续变好 |
| Agent 自我反思修改 | 容易松散、不可控,可能越改越差 |
| 手工 A/B 测试 prompt | 可控但成本高,难规模化 |
SkillOpt 的想法是:把一份 Markdown skill 文档视为冻结 Agent 的“外部可训练状态”,用类似深度学习优化器的纪律来训练它。它引入 epoch、batch size、learning rate、validation gate、slow update、meta skill 等机制,让自然语言技能也能通过反馈迭代,而不是只靠一次性提示词工程。
4. 它主要能做什么
| 能力 | 说明 | 售前价值 |
|---|---|---|
| 训练 Markdown skill | 从任务轨迹和评分结果中提炼 add/delete/replace 编辑,更新技能文档 | 将专家经验、失败教训沉淀成可复用资产 |
| 固定目标模型 | 不修改目标 LLM 权重,只优化外部 skill 文档 | 更适合企业已有模型/Agent,不需要微调基础模型 |
| 验证门控更新 | 候选编辑只有在 held-out validation score 严格提升时才接受 | 降低“越优化越差”的风险,便于售前讲可控性 |
产出 best_skill.md | 最终部署的是一个普通 Markdown 文件 | 易审查、易版本管理、易接入 Codex/Claude Code 等技能体系 |
| 多后端支持 | Release 中提到支持 OpenAI、Azure OpenAI、Claude、Qwen、MiniMax 等 | 适合多模型选型和国产/私有化路径评估 |
| 多 benchmark 支持 | 内置 SearchQA、DocVQA、ALFWorld、OfficeQA、SpreadsheetBench、LiveMath 等 | 可用于不同 Agent 任务类型的研发评测 |
| WebUI dashboard | 可选 Gradio WebUI 监控训练 | 方便研发团队观察实验过程 |
| SkillOpt-Sleep 预览 | 夜间离线复盘 coding agent 历史会话,挖掘 recurring tasks 并生成技能建议 | 可包装为“Agent 使用越多越会积累组织经验”的概念验证 |
| 插件生态雏形 | 仓库包含 Claude Code、Codex、Copilot、Devin、OpenClaw 等插件目录 | 说明它在探索与主流 coding agent 的集成 |
5. 技术原理:把深度学习训练思想搬到文本空间
SkillOpt 的训练循环可以用下面这张表解释:
| 深度学习概念 | SkillOpt 对应概念 | 解释 |
|---|---|---|
| 模型参数 | Skill document | Markdown 技能文档就是可训练状态 |
| Forward pass | Rollout | 目标 Agent 使用当前 skill 去做任务,产生轨迹和分数 |
| Loss / error | 失败轨迹、低分样本 | 用评分器判断哪些任务没做好 |
| Backward pass | Reflect | 优化器模型分析轨迹,提出编辑 patch |
| Gradient | Add / delete / replace edits | 对 skill 文档的结构化编辑 |
| Learning rate | 每步可接受的编辑数量预算 | 控制每次修改幅度,避免过度更新 |
| Gradient clipping | Rank / clip edits | 只选最相关的一部分编辑 |
| Validation set | Selection split / validation gate | 候选 skill 必须在验证集提升才接受 |
| Checkpoint | best_skill.md | 保存最佳验证表现的技能文档 |
| Momentum / memory | Slow update / meta skill | 在 epoch 边界总结长期策略和防遗忘 |
核心流程如下:
6. 适用场景
6.1 Agent 技能沉淀和持续优化
适合客户已经在使用或准备建设 Agent,但遇到“提示词写了很多、经验散落在文档/群聊/工单里、不同团队重复踩坑”的情况。SkillOpt 的卖点是把失败轨迹转化为可审查的技能文档更新,形成组织可复用的 Agent 操作经验。
6.2 可评测任务的 prompt / skill 自动优化
如果客户有明确任务集和评分标准,例如问答准确率、表格处理正确率、代码任务通过率、文档抽取准确率,SkillOpt 可以作为“自动化 prompt 优化器”或“skill 优化器”用于研发实验。
6.3 Coding Agent 的长期记忆 / 夜间复盘
SkillOpt-Sleep 预览版面向 Claude Code、Codex、Copilot 等本地 coding agent,思路是夜间回看历史会话、挖掘重复任务、离线 replay,再���验证通过的经验整理为长期技能。这个方向很适合售前讲“企业编码助手如何积累组织习惯、项目规范和常见修复经验”。
6.4 企业 Agent 平台能力评测
SkillOpt 内置多个 benchmark,并允许新增 benchmark。对于企业要建设 Agent 平台、比较模型和 Agent harness 的场景,可以把它作为研发评测/优化链路的一部分。
6.5 专家经验产品化
在运维、财务、法务、数据分析、Office 自动化等领域,专家知道“怎么做才不容易错”。SkillOpt 可以尝试把这些经验写成初始 skill,再通过真实任务和验证集持续改进。
7. 不太适合的场景
| 场景 | 原因 |
|---|---|
| 没有可评测信号的开放式创作 | SkillOpt 强依赖 rollout 评分和 validation gate;没有评分器就很难判断编辑是否真的变好 |
| 只想要开箱即用的企业 SaaS | SkillOpt 是开源研究/开发框架,不是完整商业平台 |
| 任务样本极少、不可复现 | 缺少 train/validation/test 分割会削弱优化可靠性 |
| 实时在线推理优化 | SkillOpt 的优势是离线训练 skill;在线推理时不增加模型调用 |
| 高噪声评分器 | 如果评分不稳定,优化器会学习错误信号 |
| 需要模型参数级能力提升 | 它不微调模型权重;模型本身能力不足时,skill 优化只能有限补偿 |
| 对 LLM 调用成本极敏感 | 训练阶段需要大量 rollout、反思、评估调用,PoC 前要估算预算 |
8. 怎么用
8.1 安装
官方安装方式:
git clone https://github.com/microsoft/SkillOpt.git
cd SkillOpt
pip install -e .PyPI 方式:
pip install skillopt可选依赖:
pip install -e ".[webui]"
pip install -e ".[claude]"
pip install -e ".[qwen]"
pip install -e ".[alfworld]"8.2 配置模型密钥
官方文档要求至少配置一个模型后端,例如 Azure OpenAI、OpenAI、Anthropic Claude 或本地 Qwen。
AZURE_OPENAI_ENDPOINT=https://your-resource.openai.azure.com/
AZURE_OPENAI_API_KEY=your-key
OPENAI_API_KEY=sk-...
ANTHROPIC_API_KEY=sk-ant-...8.3 运行第一个实验
官方推荐用 SearchQA,因为相对最快:
python scripts/train.py --config configs/searchqa/default.yaml训练输出通常保存在:
outputs///
├── steps/
├── slow_update/
├── meta_skill/
├── skills/
├── best_skill.md
├── history.json
└── config.yaml 评估最佳技能:
python scripts/eval_only.py \
--config configs/searchqa/default.yaml \
--skill outputs/searchqa//skills/best_skill.md 8.4 启动 WebUI
pip install -e ".[webui]"
python -m skillopt_webui.app默认端口为 7860。
8.5 使用已有 checkpoint skill
仓库 ckpt/ 目录提供了论文相关的一批 GPT-5.5 optimized skills,例如 SearchQA、ALFWorld、DocVQA、OfficeQA、SpreadsheetBench、LiveMath。它们不是通用工具,而是用于复现实验或作为可移植技能 artifact 参考。
9. 架构/部署/集成方式
9.1 主要模块
| 模块 | 作用 |
|---|---|
skillopt/engine | 训练主流程 |
skillopt/gradient | 轨迹反思、编辑 patch 聚合 |
skillopt/optimizer | 编辑选择、学习率、slow update、meta skill 等 |
skillopt/evaluation | 验证 gate |
skillopt/envs | 内置 benchmark 适配器 |
skillopt/model | Azure OpenAI、OpenAI、Claude、Qwen、MiniMax、Codex/Claude Code harness 等后端 |
skillopt_webui | Gradio WebUI |
skillopt_sleep | deployment-time companion 预览能力 |
plugins/ | Claude Code、Codex、Copilot、Devin、OpenClaw 等集成探索 |
9.2 企业落地时的典型形态
售前要强调:真正可落地的 SkillOpt 项目不是“装一下就自动变强”,而是要把任务数据、评分器、验证集、技能发布流程和审查机制一并设计好。
10. 售前可以怎么讲
面向业务方
| 客户关注点 | 推荐话术 |
|---|---|
| Agent 老是犯同样错误 | “SkillOpt 的价值是把失败经验沉淀成可复用技能,而不是每次靠人工重新调 prompt。” |
| 组织经验难沉淀 | “它产出的是 Markdown 技能文档,可以审查、版本化、复用,也可以放进企业 Agent 的技能库。” |
| 不想训练模型 | “它不改模型权重,只优化外部技能文档,对企业已有模型和闭源模型更友好。” |
| 担心优化后变差 | “它引入验证集 gate,只有候选 skill 在 held-out 验证集上变好才接受。” |
| Coding Agent 怎么越用越懂项目 | “SkillOpt-Sleep 的方向是夜间复盘历史会话,挖掘重复任务并生成经过验证的长期技能。” |
面向技术方
| 技术问题 | 推荐说明 |
|---|---|
| 需要什么输入 | “需要任务数据集、初始 skill、可执行 rollout、评分器、模型 API。” |
| 产出是什么 | “产出 best_skill.md,本质是可部署的自然语言技能。” |
| 是否增加线上推理成本 | “训练阶段会增加调用成本;部署后 skill 是静态文档,不额外增加推理模型调用。” |
| 如何扩展自己的任务 | “实现 dataloader、rollout/scorer、EnvAdapter 和 YAML config,再注册 benchmark。” |
| 怎么控制质量 | “用 train/validation/test 分割、validation gate、人工 review、版本化发布来控制。” |
11. PoC 建议
11.1 适合的 PoC 主题
| PoC 主题 | 为什么适合 |
|---|---|
| 企业知识库问答技能优化 | 有标准答案或可人工标注,容易做准确率评估 |
| Spreadsheet / Office 自动化 | 输出可比较,便于做自动评分 |
| Coding Agent 项目规范沉淀 | 可以基于测试通过率、lint、review checklist 评估 |
| 客服/运维 SOP Agent | 有历史工单、标准流程、明确成功标准 |
| 数据分析 Agent | 有固定分析任务和预期结果,适合 skill 化 |
11.2 PoC 范围
| 项目 | 建议 |
|---|---|
| 时间 | 2-4 周比较合理 |
| 数据 | 至少准备几十到几百条可评分任务,划分 train/validation/test |
| 初始 skill | 先由领域专家写一个 seed skill,不建议完全空白开始 |
| 模型 | 先用能力强且稳定的模型跑通,再评估国产/私有模型 |
| 指标 | 准确率、任务成功率、失败类型减少、skill 长度、编辑接受率、训练成本 |
| 风险动作 | 只做离线评测或沙箱任务,不直接操作生产系统 |
11.3 验收指标示例
| 指标 | 建议目标 |
|---|---|
| held-out test 提升 | 相比无 skill 或人工 seed skill 有明确提升 |
| 验证集 gate 通过率 | 不能只看训练集提升,要看验证集是否稳定 |
| skill 可读性 | 领域专家能读懂、能审查、能解释 |
| 线上额外成本 | 部署后不增加额外反思调用 |
| 可迁移性 | 同一 skill 在相邻任务或相邻模型上仍有帮助 |
12. 风险和注意事项
| 风险 | 说明 | 应对 |
|---|---|---|
| 项目成熟度 | PyPI 版本为 0.1.0,classifiers 标注 Alpha,SkillOpt-Sleep 是 preview | 先做研发 PoC,不要直接承诺生产级平台 |
| 成本不可忽视 | 训练阶段需要目标模型 rollout 和优化器反思调用 | 先估算样本量、epoch、batch size、模型单价 |
| 评分器决定上限 | 错误或噪声评分会导致优化方向错误 | 先建设可靠 eval,必要时人工抽检 |
| 数据泄露 | 训练���本、轨迹和失败案例可能包含敏感信息 | 使用脱敏数据、私有模型或企业网关 |
| 过拟合验证集 | 如果 validation 太小或任务分布偏,skill 可能只适应局部样本 | 严格保留 test split,定期更换/扩充测试集 |
| 技能文档膨胀 | 持续追加规则可能变长、冲突或难维护 | 控制 learning rate、定期人工 review 和重写整理 |
| 不能替代模型能力 | 模型本身不会推理或不会工具调用时,skill 提升有限 | 模型选型和 task design 要先验证 |
| 企业集成复杂度 | 需要数据管道、执行沙箱、评分器、版本管理 | 作为研发平台组件规划,不作为单点工具售卖 |
13. 与相关方案的区别
| 方案 | 区别 |
|---|---|
| Prompt 工程 | Prompt 工程多是人工经验驱动;SkillOpt 强调基于轨迹和验证集的系统化迭代 |
| Prompt optimizer | 一些优化器只优化一次 prompt;SkillOpt 更像训练循环,有 epoch、lr、gate、slow/meta update |
| 微调 / LoRA | 微调改模型权重;SkillOpt 改外部 Markdown skill,更轻量、可审查、部署简单 |
| RAG | RAG 解决知识检索;SkillOpt 解决“怎么做任务”的策略和操作技能 |
| Agent Memory | Memory 常存事实或经历;SkillOpt 更强调把经历固化为经过验证的任务策略 |
| Auto-reflection Agent | 普通自反思可能不稳定;SkillOpt 的验证门和 bounded edits 更可控 |
14. 我的售前判断
SkillOpt 是一个很适合“前沿 Agent 能力建设”话题的项目。它把客户常见的痛点讲得很准:Agent 不是只需要更强的模型,还需要能从失败中沉淀技能、能被验证、能版本化、能迁移的长期能力。对于有研发团队、有评测意识、有 Agent 平台规划的客户,它可以作为“Agent 持续优化体系”的技术参考或 PoC 工具。
但售前表达要稳一点:SkillOpt 当前更像研究框架和开发者工具,不是现成企业平台。真正能落地的前提是客户有可评分任务、有数据集、有模型预算、有工程团队做集成。最推荐的切入方式是做一个窄场景 PoC,例如知识库问答、表格处理、代码修复规范、工单 SOP,而不是一上来承诺“所有 Agent 自动进化”。
如果客户正在建设 AI Coding、Agent 平台、企业知识助手或自动化办公助手,SkillOpt 可以成为一个非常好的方案亮点:我们不仅能写 prompt,还能搭建一套“经验采集 → 任务回放 → 技能优化 → 验证门控 → 人工审查 → 发布”的持续改进闭环。
15. 常见客户 Q&A
| 问题 | 回答建议 |
|---|---|
| SkillOpt 是不是模型微调? | 不是。它不修改模型权重,而是优化外部 Markdown skill 文档。 |
| 它能不能直接让我们的 Agent 变强? | 需要有任务集、评分器和验证集。它提供优化框架,但不是无数据、无评测的魔法按钮。 |
| 线上推理会不会更慢? | 部署后只是把 best_skill.md 加给 Agent 使用,原则上不增加额外反思调用;训练阶段才有额外成本。 |
| 可以私有化吗? | 代码 MIT 开源,支持多模型后端;但私有化还要看客户模型 API、数据安全、运行环境和依赖。 |
| 适合哪些 Agent? | 最适合可重复、可评分、错误模式可归纳的任务型 Agent,例如问答、表格、代码、SOP、Office 自动化。 |
| 如果评分器不准怎么办? | 那优化就可能走偏。PoC 的第一步应是建设可靠 evaluation,而不是直接堆训练轮数。 |
| SkillOpt-Sleep 可以直接用于生产吗? | 官方标注 preview,适合作为演示和内部试点,生产需要谨慎评估接口稳定性和安全。 |