1. 模型概览
| 项目 | 信息 |
|---|---|
| 模型页 | nvidia/LocateAnything-3B |
| 官方项目页 | LocateAnything |
| 在线 Demo | Hugging Face Space |
| 代码入口 | NVlabs/Eagle/Embodied |
| 论文 | arXiv:2605.27365 |
| 模型类型 | Transformer-based Vision-Language Model |
| 参数规模 | 约 3B;Hugging Face safetensors 显示 BF16 参数约 3.83B |
| Base model | Qwen/Qwen2.5-3B-Instruct |
| Vision encoder | MoonViT / MoonViT-SO-400M |
| Pipeline | image-text-to-text |
| Library | Transformers,需 trust_remote_code=True |
| License | NVIDIA License,非商业研究/评估用途 |
| Hugging Face 热度 | 约 570k downloads、2.4k likes,检查日期:2026-06-27 |
| 最近修改 | 2026-06-12,检查日期:2026-06-27 |
| 发布日期 | 模型卡标注 GitHub / HF / Demo / Webpage 于 2026-05-26 发布 |
| 运行平台 | Linux;推荐 NVIDIA GPU;文档列出 A100、H100、L40、RTX 4090、Blackwell 等 |
2. 关键示意图
能力总览与 PBD 对比
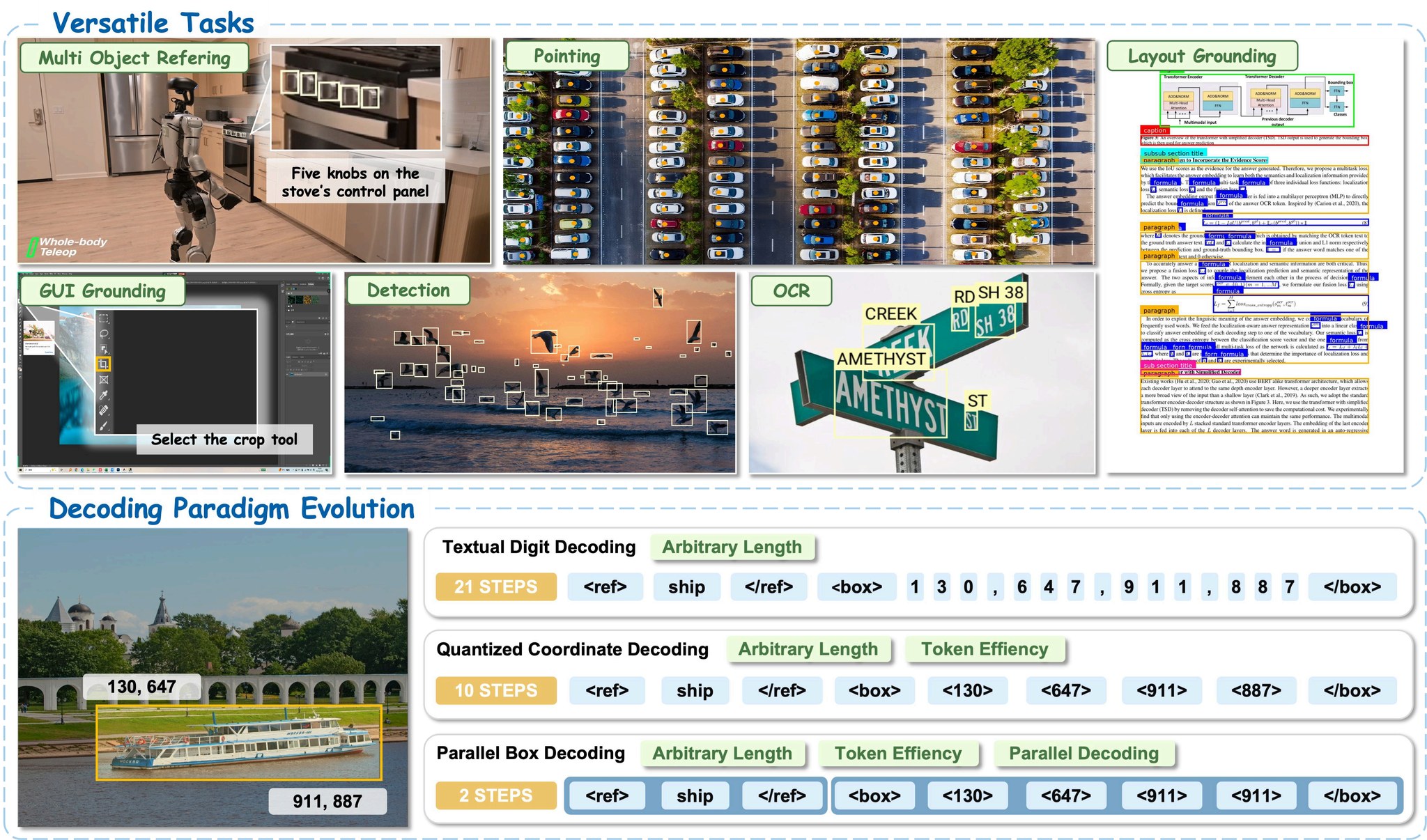
这张图最适合售前开场使用:上半部分展示 LocateAnything 覆盖多物体定位、点选定位、版面定位、GUI grounding、检测和 OCR;下半部分展示它和传统坐标 token 解码的区别。传统方法需要逐 token 生成坐标,PBD 将一个 box 作为原子单元并行生成。
模型架构与结构化块输出
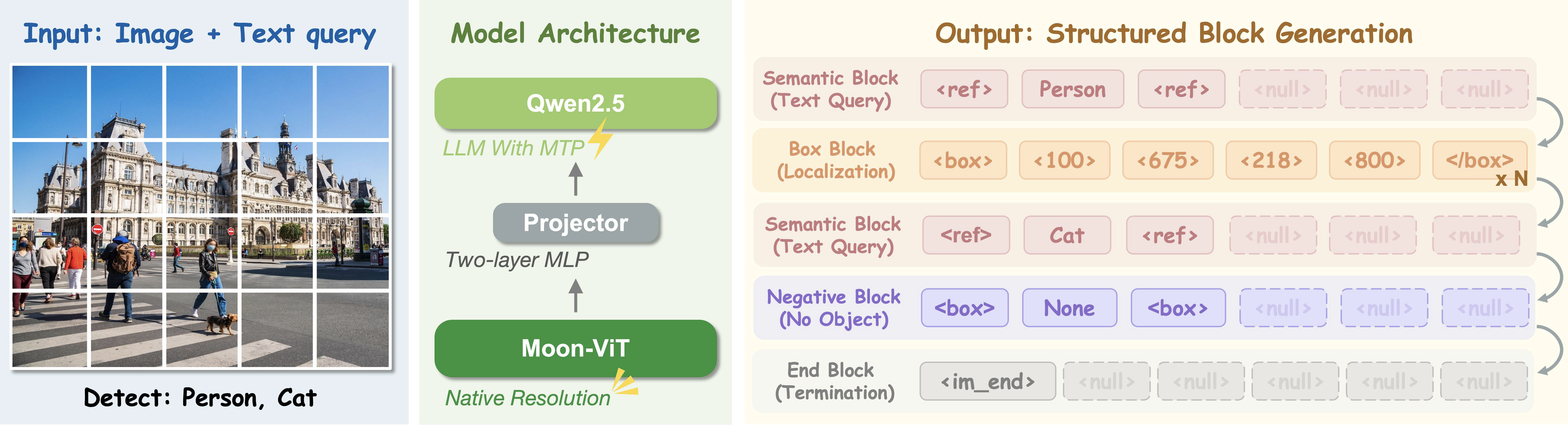
架构图说明:输入是图像 + 文本查询;视觉编码器为 Moon-ViT,语言侧为 Qwen2.5,中间通过两层 MLP projector 连接;输出不是普通自然语言,而是包含 semantic block、box block、negative block、end block 的结构化定位序列。
Parallel Box Decoding 方法图
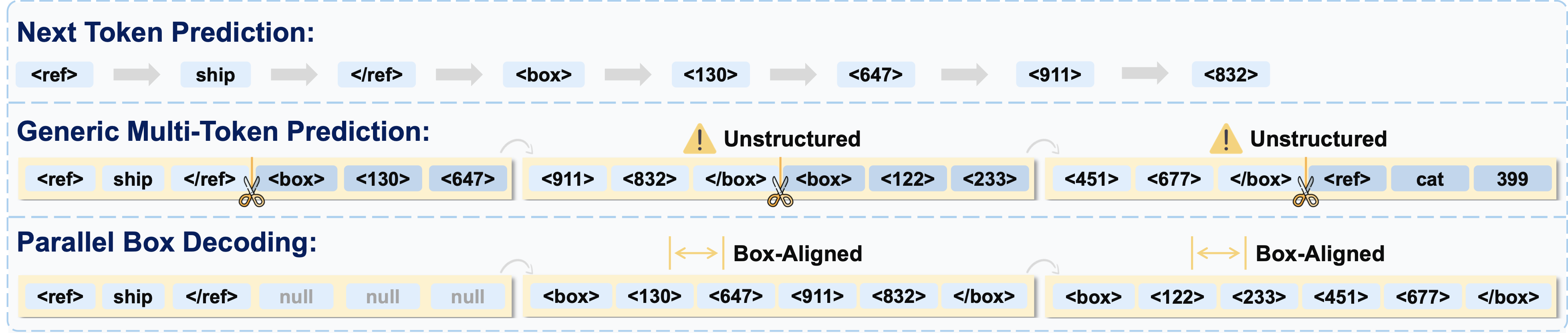
这张图适合解释核心技术创新:把一组 box 坐标视作耦合几何结构,而不是彼此独立的 token。对于定位任务,这有助于减少坐标顺序生成带来的延迟和几何不一致。
数据覆盖
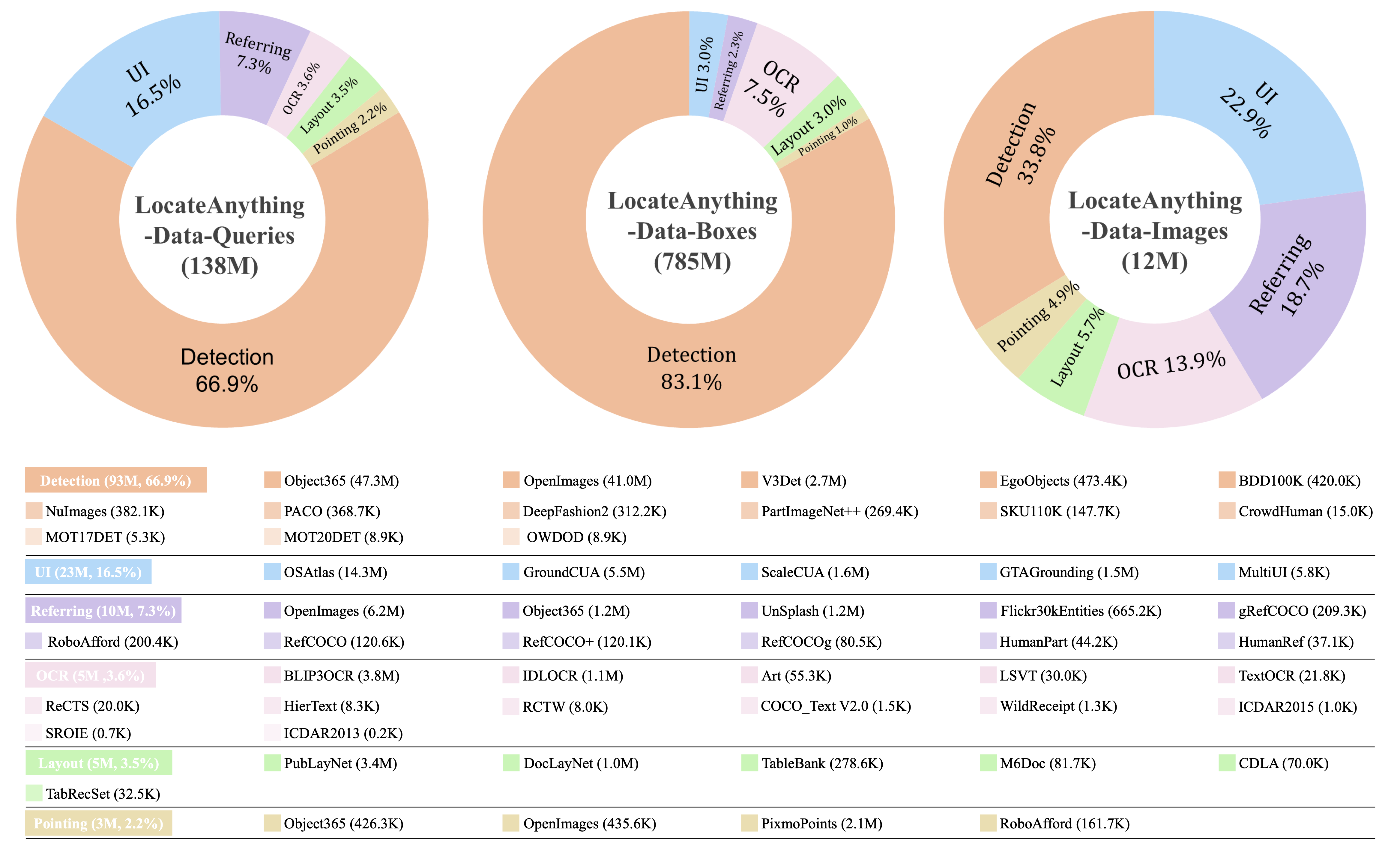
官方资料说明训练数据覆盖自然场景、机器人、驾驶、GUI、文档、OCR、开放世界检测等多域。模型卡提到训练集包含 12M unique images、约 140M 自然语言 queries、785M bounding boxes。
GUI / OCR / Detection 等 benchmark 图
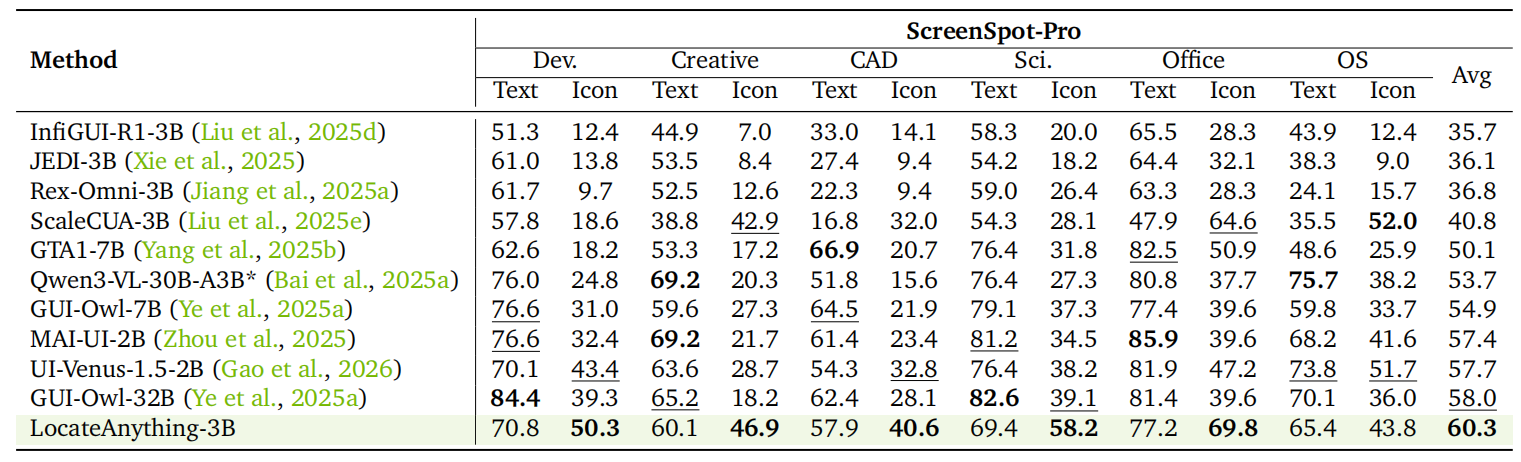
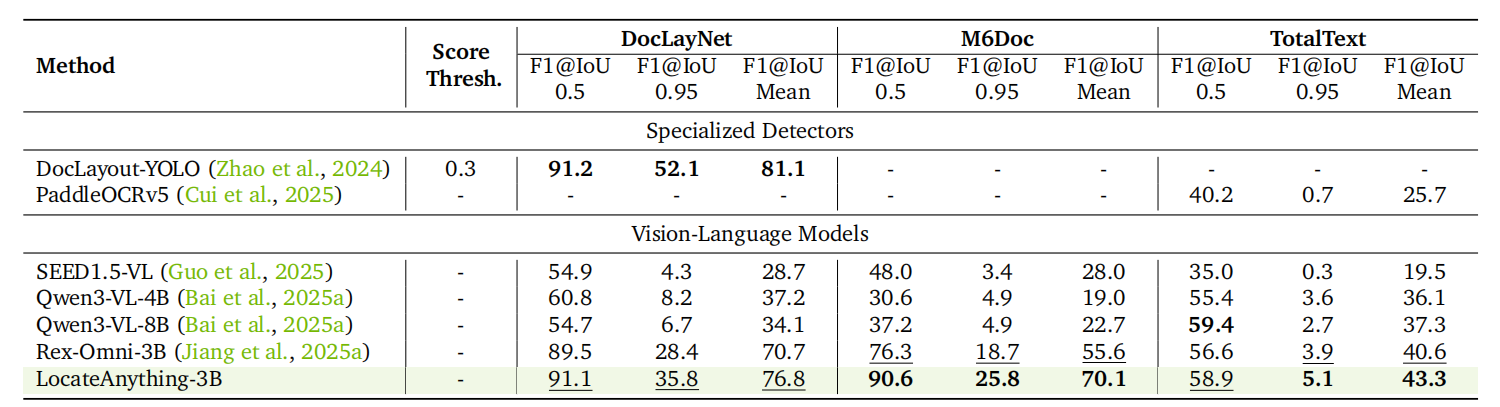
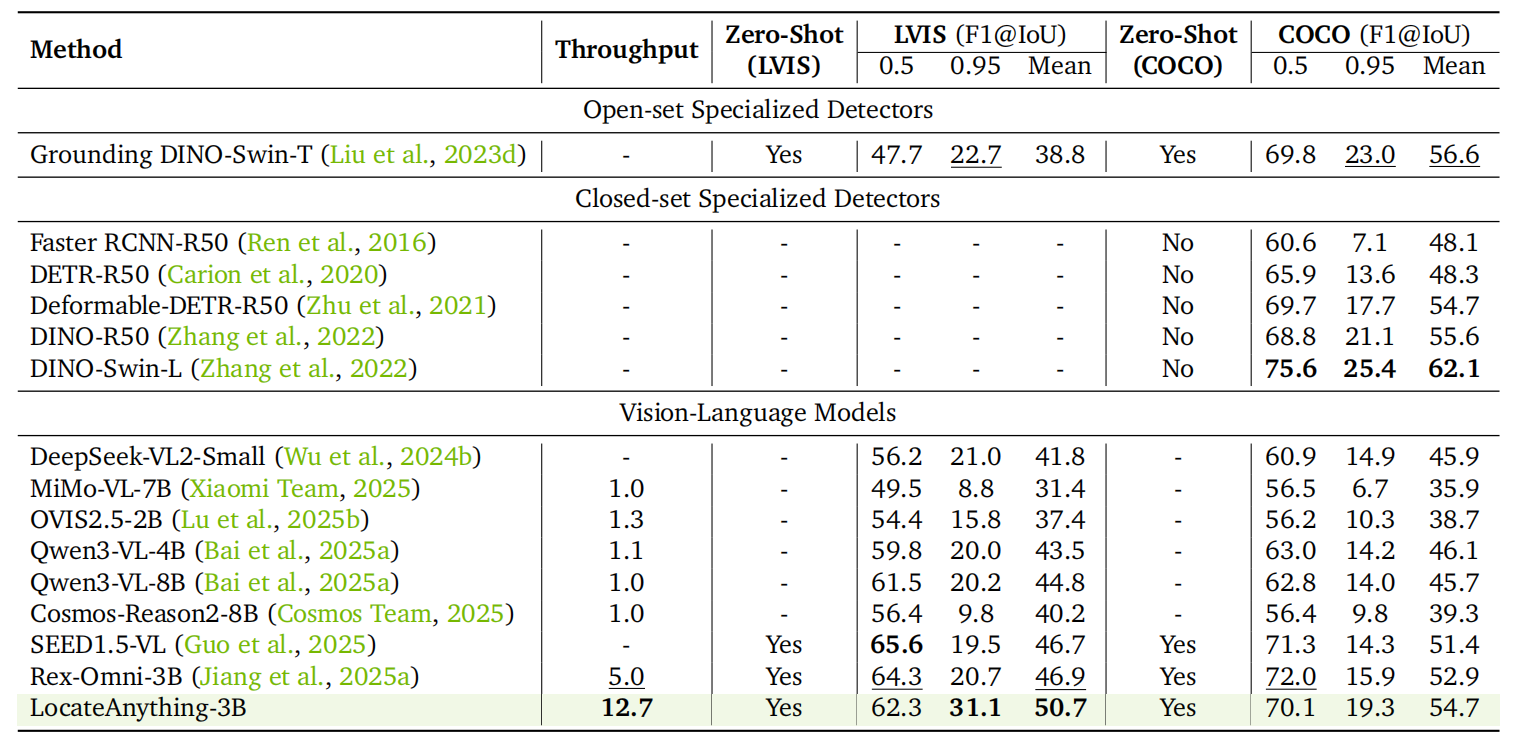
这些图分别对应 GUI grounding、layout/OCR、通用目标检测等能力,适合放在客户材料中说明它不是单一检测器,而是面向多种视觉定位任务的通用 grounding 模型。
3. 它到底能做什么
LocateAnything-3B 的核心任务可以概括为:给它一张图片和一句自然语言指令,它输出目标在图像中的位置,通常是 bounding box 或 point。
| 能力 | 举例 | 业务价值 |
|---|---|---|
| 开放类别目标检测 | “定位所有 person、car、bicycle” | 不需要为每个类别单独训练传统检测器,更适合长尾对象 |
| 指代表达 grounding | “定位穿红衣服的人”“左侧第二辆车” | 支持更自然的人机交互和视觉问答落地 |
| 多物体密集检测 | 拥挤场景中定位大量对象 | 适合安防、交通、遥感、仓储盘点等 |
| GUI 元素 grounding | “定位搜索按钮”“点击 crop tool” | 适合视觉 GUI Agent、RPA 增强、Computer Use |
| OCR / 文本定位 | “检测所有文本”“定位某个路牌文字” | 文档理解、票据识别、场景文字检测 |
| 文档版面 grounding | 定位标题、段落、公式、表格等区域 | 适合 PDF/文档智能解析、版面还原 |
| 点选定位 | “Point to the traffic light” | 适合机器人、远程操控、具身智能交互 |
| 机器人 / 自动驾驶感知 | 识别空间对象并输出位置 | 可作为 Physical AI 感知模块的候选技术 |
4. 核心技术亮点
4.1 Parallel Box Decoding
传统 VLM grounding 通常把 2D box 坐标序列化成多个 1D token,再逐 token 自回归生成。这有两个问题:第一,坐标之间天然是耦合的几何结构,但逐 token 生成会削弱几何一致性;第二,严格串行生成会成为推理瓶颈。
LocateAnything 的 PBD 将 box 或 point 作为原子几何单元并行解码。官方论文摘要称,PBD 同时改善了解码吞吐和定位准确率,并推动 speed-accuracy frontier。
4.2 三种推理模式
| 模式 | 说明 | 适合场景 |
|---|---|---|
fast | MTP only,不回退到自回归 | 简单场景、追求速度 |
slow | 纯 autoregressive decoding | 追求稳定性和准确性的离线任务 |
hybrid | 默认先并行,遇到格式异常或空间歧义回退到自回归 | 推荐默认,兼顾速度和效果 |
模型卡建议使用 max_new_tokens=8192 和 generation_mode="hybrid",以避免输出被截断,并平衡速度与准确率。
4.3 大规模多域数据
模型卡和项目页强调 LocateAnything-Data 包含大规模、多领域训练数据:
| 维度 | 官方描述 |
|---|---|
| 图像规模 | 12M unique images |
| Query 规模 | 模型卡写约 140M natural-language queries;项目页和论文摘要强调 138M+ training samples / language queries |
| Box 规模 | 785M bounding boxes |
| 数据域 | grounding、open-world grounding、dense detection、scene text、GUI、document layout、OCR、robotics/driving 等 |
| 标注方式 | 人工、开源标注、模型辅助、合成标注、自动验证 |
4.4 高吞吐 batch inference 工具
模型仓库不仅给了 model weights,还提供 batch_infer.py、batch_utils 和 kernel_utils。其中 la_flash 后端用于 FlashAttention varlen sparse range 计划,目标是避免构造 dense [B,H,Q,K] attention mask。
模型卡给出的 A100 4K 图像 probe 示例:
| Backend | Attention Path | Time | Peak Reserved Memory |
|---|---|---|---|
sdpa | Dense SDPA masks | 8.2600s | 35.12GB |
la_flash | FlashAttention sparse range plan | 8.0314s | 11.71GB |
售前解释:它不仅是模型权重,还包含面向高分辨率、多目标 batch 检测的推理工程优化思路。
5. 适用场景
5.1 GUI Agent / Computer Use
LocateAnything 能做 GUI element grounding:给定屏幕截图和自然语言指令,定位按钮、菜单、图标或区域。它可作为视觉 GUI Agent 的感知模块,帮助 Agent 从“理解界面截图”走向“知道该点击哪里”。
适合场景:
| 场景 | 价值 |
|---|---|
| 桌面/网页自动化 | 在缺少 DOM 或页面结构不可用时,通过视觉定位元素 |
| 软件测试 | 根据自然语言测试步骤定位 UI 控件 |
| RPA 增强 | 让 RPA 从坐标录制升级为语义控件定位 |
| 远程运维 | 在截图/视频流中定位操作目标 |
5.2 文档理解和 OCR/Layout
它支持 layout grounding 和 OCR localization,可用于定位标题、段落、公式、表格、文本块、特定字段等。
适合场景:
| 场景 | 价值 |
|---|---|
| PDF/扫描件解析 | 在复杂版面中定位字段和区域 |
| 票据/合同处理 | 找到关键字段位置,辅助结构化抽取 |
| 文档审核 | 识别文档区域并与规则/问答结合 |
| 知识库构建 | 提升图文混排文档切片和版面理解 |
5.3 工业视觉和质检
开放类别检测和指代表达 grounding 适合做工业视觉 PoC,尤其是客户对象种类多、长尾缺陷多、传统检测器维护成本高的情况。
注意:商业落地不能直接使用该模型许可证,需要把它作为技术验证、选型参考或与 NVIDIA 商务授权沟通。
5.4 机器人 / 具身智能 / 自动驾驶
项目页和模型卡都提到 robotics、driving、Physical AI。LocateAnything 可作为“语言指令到视觉位置”的桥接模块,例如“抓取左边的杯子”“定位红色按钮”“指向路口信号灯”。
5.5 自动标注和数据生产
它可以用于生成 grounding / detection / pointing 的候选标注,再由人工或规则复核。适合训练数据准备、长尾对象标注、GUI 数据集构建。
6. 不太适合的场景
| 场景 | 原因 |
|---|---|
| 直接商业交付 | NVIDIA License 明确限制非商业研究/评估用途,商业使用不允许,除 NVIDIA 及其 affiliates 外 |
| CPU-only 或低端设备部署 | 官方强调 NVIDIA GPU 加速系统;3B VLM + 高分辨率输入对显存和算力有要求 |
| 极低延迟边缘端 | 虽有 PBD 和 batch 工具,但 3B 模型在嵌入式平台上仍需量化、压缩、蒸馏等优化 |
| 需要严格安全认证的生产系统 | 模型卡提示需要按 use-case-specific data 做迭代测试和验证 |
| 没有图像/截图输入的纯文本场景 | 它是视觉 grounding 模型,不是通用文本 LLM |
| 高风险自动决策 | 定位结果可能错误,需要人工复核或系统级安全冗余 |
| 多语言 grounding | 模型卡语言标注为 English,主要 prompt/query 是英语任务表达 |
7. 怎么用
7.1 安装依赖
模型卡给出的基础依赖:
pip install opencv-python-headless==4.11.0.86 transformers==4.57.1 numpy==1.25.0 Pillow==11.1.0 peft torchvision decord==0.6.0 lmdb==1.7.5PyTorch 需要按 CUDA 版本单独安装。Hopper / Blackwell GPU 可选安装 MagiAttention,用于更快的 MTP inference;未安装时会回退到 PyTorch SDPA。
7.2 Python 调用方式
模型卡提供了一个 LocateAnythingWorker 模式:启动时加载 tokenizer、processor、model,之后通过 predict() 和任务方法服务检测、grounding、OCR、GUI grounding 等请求。
简化示例:
from PIL import Image
worker = LocateAnythingWorker("nvidia/LocateAnything-3B")
img = Image.open("example.jpg").convert("RGB")
result = worker.detect(img, ["person", "car", "bicycle"])
print(result["answer"])
result = worker.ground_gui(img, "the search button", output_type="point")
print(result["answer"])输出格式中 box/point 坐标是归一化到 [0, 1000] 的 token,需要再转换成像素坐标。
7.3 支持的 Prompt 模板
| 任务 | Prompt Template | 输出 |
|---|---|---|
| Object Detection | Locate all the instances that matches the following description: [CATEGORIES]. | Box |
| Phrase Grounding | Locate a single instance that matches the following description: [PHRASE]. | Single Box |
| Multi Phrase Grounding | Locate all the instances that match the following description: [PHRASE]. | Multiple Boxes |
| Text Grounding | Please locate the text referred as [PHRASE]. | Box |
| Scene Text Detection | Detect all the text in box format. | Box |
| GUI Grounding | Locate the region that matches the following description: [PHRASE]. | Box |
| GUI Pointing | Point to: [PHRASE]. | Point |
7.4 Batch inference
python batch_infer.py \
--model nvidia/LocateAnything-3B \
--attn la_flash \
--scheduler pipeline \
--batch-size 4 \
--image /path/to/image.jpg \
--query "personcar"这个模式适合离线批量检测、自动标注和评测,不适合训练路径。
8. 售前可以怎么讲
面向业务方
| 客户关注点 | 推荐话术 |
|---|---|
| 视觉 AI 能不能听懂自然语言 | “LocateAnything 可以把自然语言描述直接转换成图像中的位置,例如定位按钮、文本、物体、文档区域。” |
| UI 自动化为什么需要它 | “当 DOM 不可用、界面是远程桌面/图片/视频流时,视觉 grounding 可以告诉 Agent 应该点击哪里。” |
| 工业视觉对象很多 | “它不是传统固定类别检测器,而是开放类别/自然语言驱动的定位模型,适合长尾对象和快速 PoC。” |
| 文档场景复杂 | “它能定位版面区域、OCR 文本和布局元素,可与 OCR/LLM 抽取流程结合。” |
| 性能亮点 | “核心 PBD 不是逐 token 生成坐标,而是并行解码 box,提高吞吐并保持几何一致性。” |
面向技术方
| 技术问题 | 推荐说明 |
|---|---|
| 模型怎么接 | “Transformers + custom code,AutoModel/AutoProcessor 加载,建议 BF16 + GPU。” |
| 输出怎么用 | “输出是结构化 token,需要解析 |
| 部署怎么做 | “可封装成 FastAPI/gRPC worker;高吞吐场景可评估 batch_infer、la_flash、MagiAttention。” |
| 能不能商用 | “当前公开模型许可证不允许商业使用。商业项目需另行授权或只把它作为技术验证参考。” |
| 和 Grounding DINO 类模型区别 | “Grounding DINO 更偏检测/grounding 专用模型;LocateAnything 是 VLM 式统一生成框架,覆盖 GUI、OCR、layout、pointing 等更多任务形态。” |
9. PoC 建议
9.1 推荐 PoC 方向
| PoC | 输入 | 输出 | 验证指标 |
|---|---|---|---|
| GUI 控件定位 | 应用截图 + 操作描述 | 按钮/区域 box 或 point | 点击命中率、任务成功率 |
| 文档版面定位 | PDF 页面截图 + 字段描述 | 字段/段落/表格位置 | IoU、字段召回率、抽取准确率 |
| 工业缺陷/对象定位 | 产线图像 + 对象/缺陷描述 | 检测框 | mAP、IoU、漏检率、误检率 |
| 遥感/交通密集检测 | 高分辨率图像 + 类别 | 多目标框 | 召回率、密集场景吞吐 |
| 自动标注 | 待标注图片 + 类别/描述 | 候选标注 | 人工修正率、标注提效 |
9.2 PoC 设计建议
| 项目 | 建议 |
|---|---|
| 数据量 | 先准备 50-200 张代表性图片,覆盖简单、中等、困难场景 |
| 标注 | 建立一小批人工 ground truth,用 IoU / point-in-mask / hit rate 评估 |
| 模式 | 默认用 hybrid;对比 fast 和 slow 的速度/准确率 |
| 资源 | 优先 H100/A100/L40/RTX 4090;记录显存、延迟、吞吐 |
| 安全 | 不直接接生产控制链路,先在沙箱或离线评测中验证 |
| 许可 | 明确 PoC 仅用于研究/评估;商业落地需确认授权 |
9.3 验收指标示例
| 指标 | 建议目标 |
|---|---|
| GUI 点击命中率 | 常见控件 >85%,复杂/遮挡场景单独分析 |
| Box IoU@0.5 | 按业务场景设定,先看相对传统方案提升 |
| 点选命中率 | 点落在目标 mask/box 内 |
| 推理延迟 | 按单图、batch、高分辨率分别记录 |
| 人工标注提效 | 候选框可用率、人工修正时间减少 |
| 失败类型 | 小目标、遮挡、反光、密集重叠、文本模糊等分类统计 |
10. 风险和注意事项
| 风险 | 说明 | 建议 |
|---|---|---|
| 许可限制 | NVIDIA License 限制非商业研究/评估用途,商业使用不允许 | 售前必须明确;商业项目需谈授权或换可商用模型 |
| 模型卡非通用生产承诺 | 明确是 research model variant,需 use-case-specific 测试 | 先 PoC,不能直接承诺生产效果 |
| 高算力需求 | 3B VLM + 高分辨率图像对 GPU/显存要求高 | 做硬件 sizing,评估量化/蒸馏/裁剪 |
| 自定义代码加载 | 需要 trust_remote_code=True,有供应链安全审查要求 | 在企业内网镜像、代码审计、固定 commit |
| 坐标解析和后处理 | 输出是文本 token,需解析、映射、过滤 | 封装稳定 parser 和异常处理 |
| 误定位风险 | 视觉 grounding 可能受遮挡、模糊、小目标影响 | 人工确认、规则校验、多模型交叉验证 |
| 隐私和合规 | 输入图片可能包含人脸、健康信息、商业机密 | 脱敏、访问控制、日志治理 |
| 语言范围 | 主要面向英文 prompt | 中文场景需实测或做 prompt 翻译层 |
11. 与相关技术的关系
| 技术 | 与 LocateAnything 的关系 |
|---|---|
| Grounding DINO | 经典开放词汇检测/grounding 模型;LocateAnything 更强调 VLM 统一生成、PBD 和多任务覆盖 |
| SAM / SAM 3 | SAM 偏分割;LocateAnything 偏自然语言到 box/point,可作为 SAM 的 prompt 生成器 |
| OCR 引擎 | OCR 负责文字识别;LocateAnything 可补充文本区域定位和版面 grounding |
| 多模态大模型 | 通用 VLM 能理解图像;LocateAnything 更专注高质量视觉定位输出 |
| RPA / GUI Agent | LocateAnything 可作为视觉定位模块,和操作执行器、流程编排器结合 |
| 传统检测器 | 传统检测器需要固定类别训练;LocateAnything 更适合开放类别和自然语言描述 |
12. 我的售前判断
LocateAnything-3B 是一个很适合“视觉 Agent / Physical AI / GUI grounding”方向交流的模型。它把很多客户关心的问题串起来了:AI 不仅要看懂图,还要告诉系统“目标在哪里”;不仅能识别常见物体,还能通过自然语言定位 GUI 控件、文档区域、OCR 文本和密集目标。
它的售前价值在于提供一个强 demo:客户输入一句自然语言,模型直接在复杂图像里定位目标。对于 GUI 自动化、文档智能、工业质检、机器人和自动驾驶感知,这类能力非常直观。
但它当前不适合作为直接商用交付的开源模型,因为许可证限制非常关键。更合适的定位是:用于研究评估、PoC 验证、方案原型、技术路线选型,或者作为与 NVIDIA 生态/授权合作的入口。正式商业方案需要提前解决授权、模型部署、硬件成本、隐私合规和稳定性验证。
13. 常见客户 Q&A
| 问题 | 回答建议 |
|---|---|
| 它能不能商用? | 当前 Hugging Face 模型采用 NVIDIA License,限制为非商业研究/评估用途,不能直接商用。商业项目需要另行确认授权。 |
| 它和普通目标检测有什么区别? | 普通检测器通常是固定类别;LocateAnything 可以用自然语言描述目标,覆盖 GUI、OCR、layout、pointing 等多任务。 |
| 它能输出什么? | 主要输出结构化文本 token,包含 |
| 它能处理中文指令吗? | 模型卡语言标注为 English,中文指令需要实测;工程上可先用翻译层转英文 prompt。 |
| 需要多大 GPU? | 官方列出 A100/H100/L40/RTX 4090 等 NVIDIA GPU,具体显存取决于分辨率、batch、模式和后端。 |
| 是否支持 TensorRT / Triton? | 模型卡写明当前 runtime engine 是 Transformers,TensorRT、TensorRT-LLM、Triton 尚未支持。 |
| 能否用于 GUI 自动点击? | 它负责定位控件位置,还需要和点击执行器、权限控制、异常确认、业务流程编排结合。 |