1. 项目概览
| 维度 | 信息 |
|---|---|
| 项目名称 | Hyper-Extract |
| GitHub | yifanfeng97/Hyper-Extract |
| 官方文档 | Hyper-Extract Docs |
| 中文文档 | Hyper-Extract 中文文档 |
| 项目定位 | LLM 驱动的智能知识抽取与知识演化框架 |
| 主要入口 | CLI:he;MCP Server:he-mcp;Python API |
| 最新版本 | v0.3.0,发布时间:2026-06-19 |
| PyPI 包 | hyperextract,要求 Python >=3.11 |
| License | Apache License 2.0 |
| 项目成熟度 | pyproject.toml 标注为 Development Status :: 3 - Alpha |
| GitHub 热度 | 约 2.8k stars、324 forks、3 issues、0 PRs,统计时间:2026-06-30 |
项目官方口号是 Smart Knowledge Extraction CLI,核心理念可以理解为:不只是让大模型“总结文档”,而是把文档稳定地抽取成可持久化、可检索、可演化、可导出的知识对象。
它和普通 RAG 工具的差别在于:普通 RAG 更偏向“切块、向量化、召回、回答”;Hyper-Extract 更强调先把文本变成结构化知识,例如人物关系图、事件时间线、空间关系图、财务实体关系、合同义务关系,再围绕这些结构做搜索、展示、问答和导出。
2. 官方关键示意图
以下图片均来自项目仓库本身,适合在售前材料中用于解释产品能力和工作流程。
2.1 项目 Logo
![]()
2.2 整体工作流示意
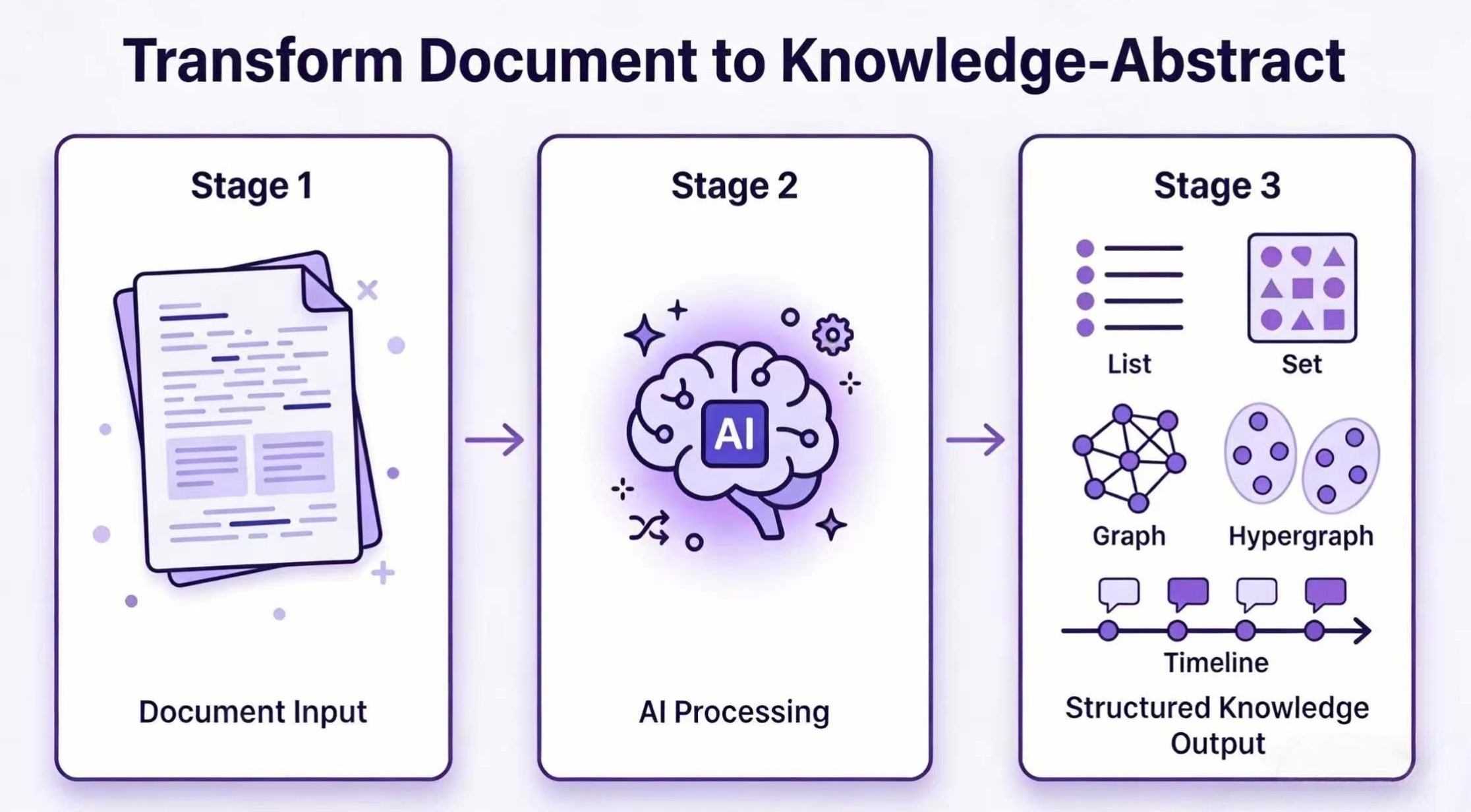
这张图适合用来讲“从文档到知识结构”的核心价值:输入非结构化文本,经过 LLM 抽取与结构化处理,最终沉淀成可查询、可展示、可导出的知识资产。
2.3 Auto-Types 知识结构矩阵
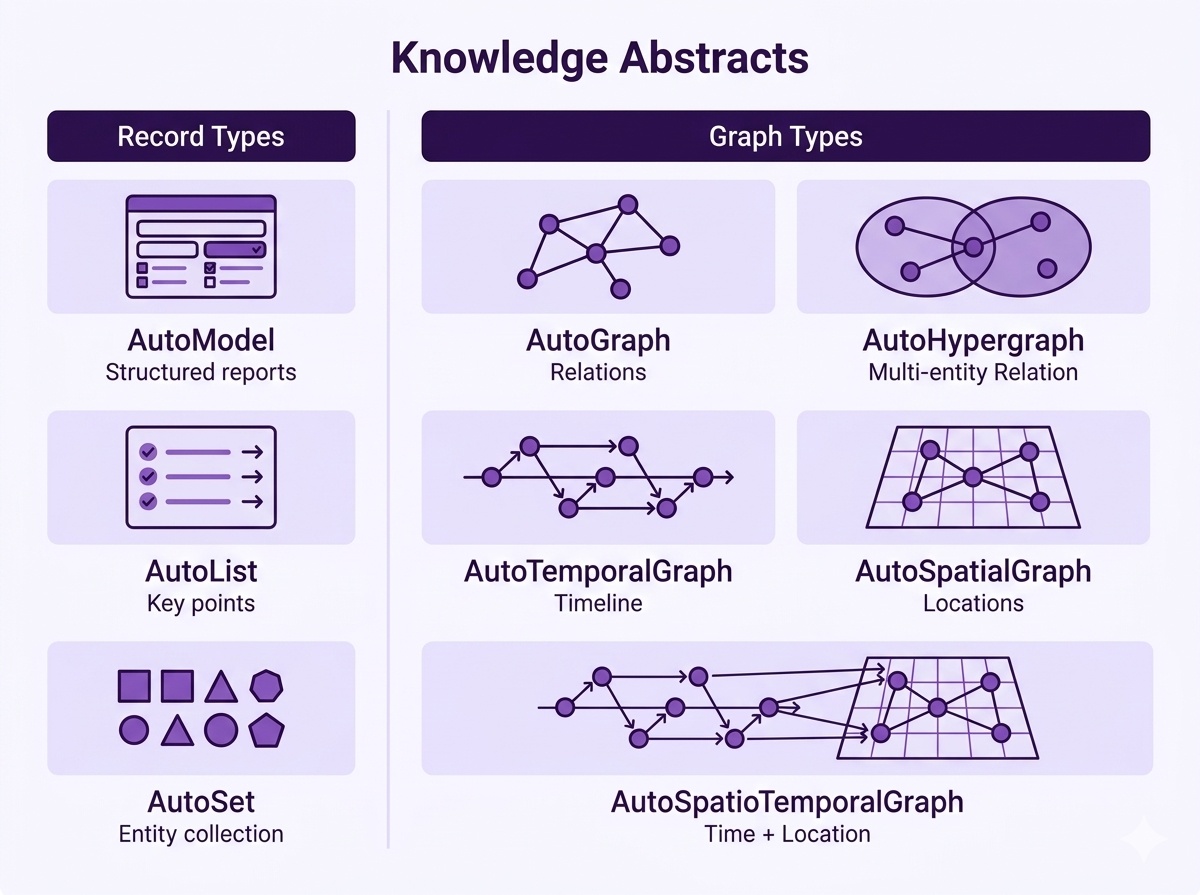
这张图是项目最值得强调的能力之一:Hyper-Extract 不只支持传统知识图谱,还支持 List、Set、Model、Hypergraph、Temporal Graph、Spatial Graph、Spatio-Temporal Graph 等多种知识结构。
2.4 中文知识图谱可视化效果
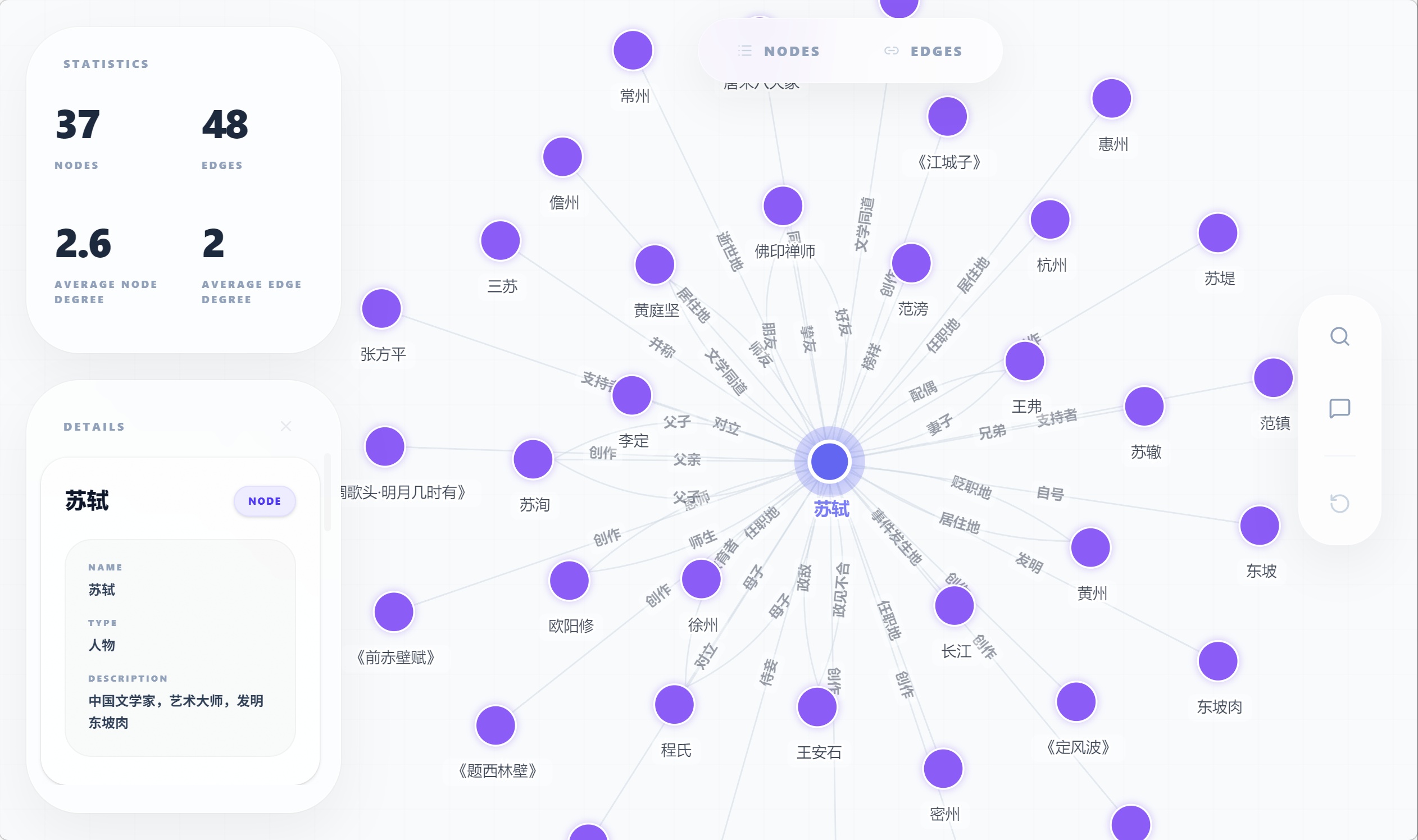
这张图适合给中文客户展示:抽取后的知识结构可以直接可视化,不只是存在 JSON 里。
2.5 架构示意图
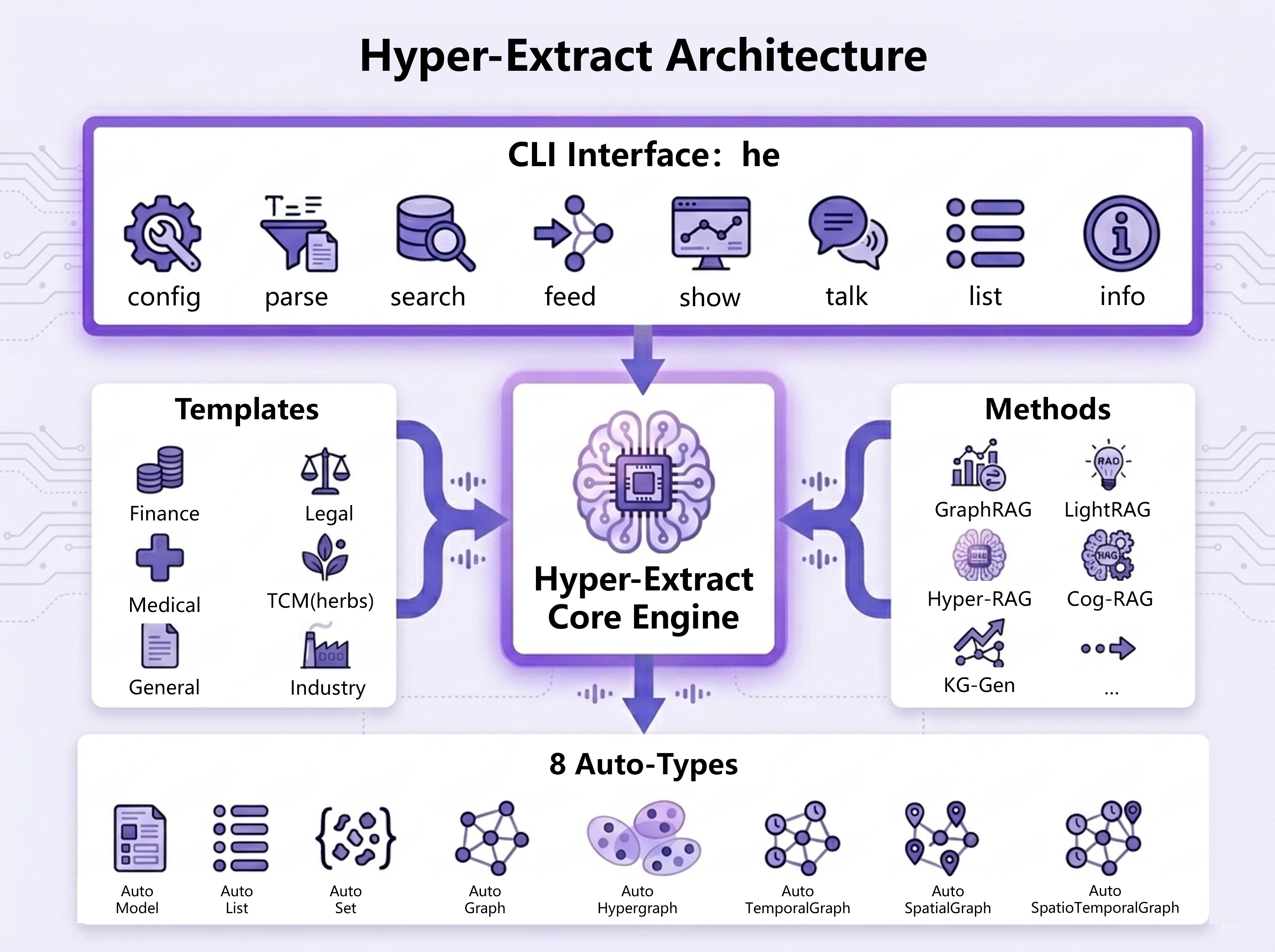
架构图可以用于技术交流:输入文本经过文本处理、LLM 抽取、结构合并,最终生成 Auto-Type 实例,再支持搜索、聊天、可视化、保存/加载等操作。
2.6 CLI 使用界面
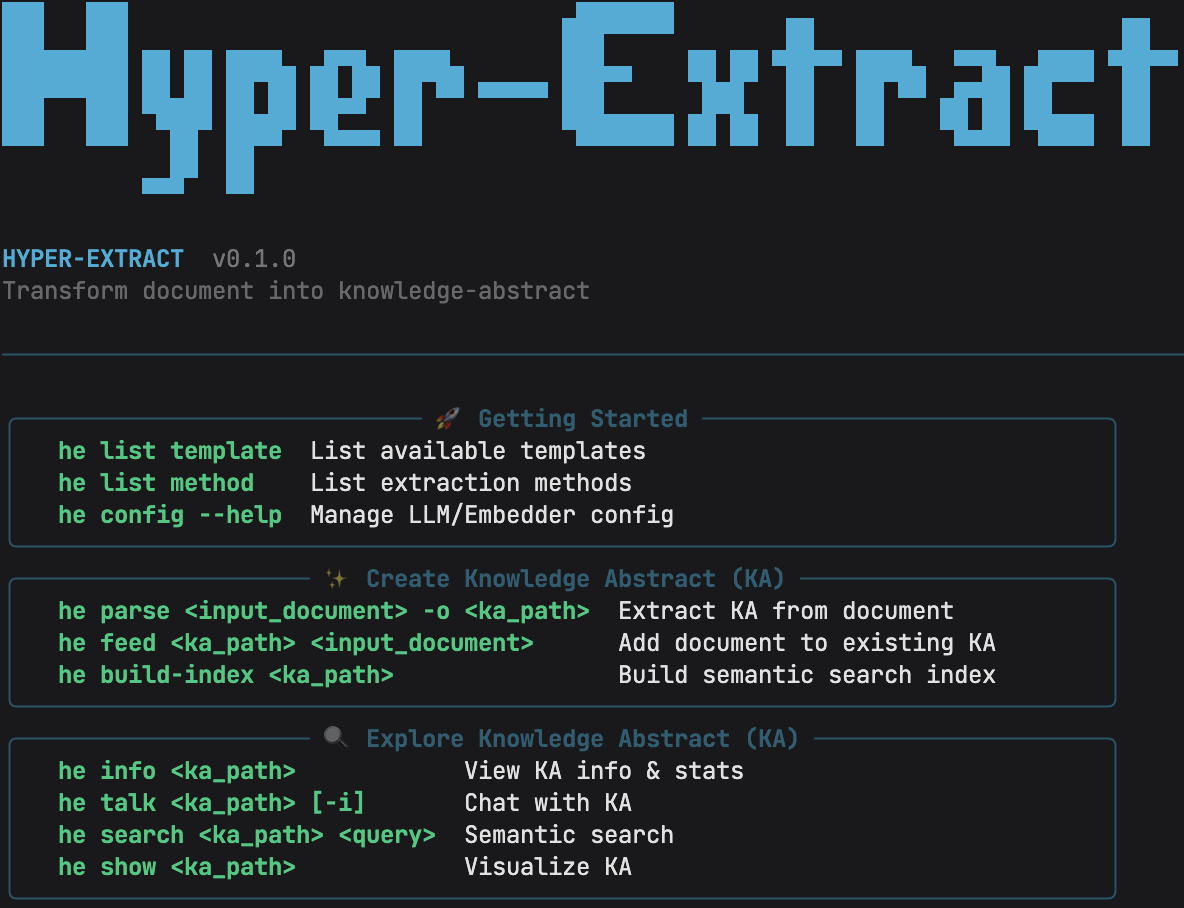
3. 它主要能做什么
3.1 把非结构化文档抽取成强类型知识对象
Hyper-Extract 的基本动作是:
he parse input.md -t general/biography_graph -o ./output/ -l zh它会根据模板和目标知识结构,把输入文档抽取为一个 Knowledge Abstract,也就是可保存、可查询、可演化的知识对象。
可抽取的结构包括:
| 类型 | 说明 | 典型用途 |
|---|---|---|
| AutoModel | 单个结构化对象 | 人物档案、产品规格、财务报告摘要 |
| AutoList | 有序列表 | 步骤、流程、时间线、事件序列 |
| AutoSet | 去重集合 | 标签、关键词、能力项、风险项 |
| AutoGraph | 二元关系知识图谱 | 人物关系、组织关系、概念关系 |
| AutoHypergraph | 多实体关系超图 | 多方协作、复杂业务事件、联合风险 |
| AutoTemporalGraph | 时间图 | 历史事件、项目里程碑、财务变化 |
| AutoSpatialGraph | 空间图 | 地理位置、设施网络、供应链空间关系 |
| AutoSpatioTemporalGraph | 时空图 | 谁在什么时间、什么地点、发生了什么 |
售前表达可以简化为:它不是只把文档“读懂”,而是把文档里的实体、关系、事件、时间、地点和业务结构“抽出来、连起来、存下来”。
3.2 提供 80+ 领域模板
项目内置 80+ YAML 模板,覆盖多个领域:
| 领域 | 可讲的客户场景 |
|---|---|
| Finance | 财报分析、公告分析、风险因素抽取、指标关系梳理 |
| Legal | 合同条款、义务关系、法律事实、合规审查 |
| Medical | 病历、指南、医学知识、疾病/症状/治疗关系 |
| TCM | 中医药、方剂、症候、药材关系 |
| Industry | 工业文档、设备说明、故障报告、流程规程 |
| General | 论文、人物、组织、百科型文档、通用知识图谱 |
这对售前很有价值,因为做 PoC 时不一定从零设计 schema,可以先用内置模板快速跑通样例,再根据客户业务做模板定制。
3.3 支持多种抽取引擎和 RAG/GraphRAG 方法
项目宣称支持 10+ Extraction Engines,包括 GraphRAG、LightRAG、Hyper-RAG、KG-Gen、Cog-RAG 等。
售前可以这样讲:
- 对简单字段抽取,可以用 Model/List/Set。
- 对实体关系密集的材料,可以用 AutoGraph。
- 对多主体关系复杂的业务,例如多家公司、多合同、多事件交织,可以尝试 Hypergraph。
- 对带时间和地点的业务,例如舆情、案件、事故、供应链,可以尝试 Temporal/Spatial/Spatio-Temporal Graph。
3.4 支持知识增量演化
除了首次解析 he parse,还可以用:
he feed ./output/ new_document.md这意味着知识对象不是一次性产物,而可以随着新文档进入而更新。对于企业知识库、行业情报、研究资料库,这一点很适合讲“持续演化的知识资产”。
3.5 支持搜索、问答和可视化
常用命令包括:
he search ./output/ "苏轼有哪些重要作品?"
he talk ./output/ -i
he show ./output/其中:
he search用于语义搜索。he talk用于基于知识对象聊天问答。he show用于可视化知识图谱。
3.6 支持 Obsidian 导出
Hyper-Extract 有一个非常适合知识管理客户的能力:
he export obsidian ./output/ -o ./vault/它会把知识图谱类结构导出成 Obsidian Markdown:
- 每个节点变成一篇 Markdown 笔记。
- 节点字段写入 YAML frontmatter。
- 关系转换成
[[wikilink]]。 - 自动生成索引页。
这对企业内部知识管理、研究团队、咨询团队、售前资料库、个人知识库都很容易讲价值。
需要注意:官方文档说明 Obsidian 导出主要支持图谱类 Auto-Type,如 AutoGraph、AutoHypergraph、AutoTemporalGraph、AutoSpatialGraph、AutoSpatioTemporalGraph;非图谱类 AutoList/AutoSet/AutoModel 不适合直接导出为 Obsidian 图谱。
3.7 支持 MCP Server
v0.3.0 中引入了 MCP Server,可通过:
pip install 'hyperextract[mcp]'
he-mcpMCP 提供的工具包括:
list_templatesinfosearchaskexport_obsidian
官方定位是只读和导出,不创建、不修改、不删除 Knowledge Abstract。售前上可以把它讲成:让 Claude Desktop、Cursor、Codex 或其他 MCP 客户端接入已有知识对象,实现“从知识库到 Agent 工具”的连接。
4. 适用场景
4.1 科研论文和技术文档理解
适合对象:
- 高校科研团队
- 企业研究院
- 技术咨询团队
- 投研/行业研究团队
可解决问题:
- 论文太多,人工读不完。
- 想快速抽取作者、方法、任务、数据集、指标、结论之间的关系。
- 想把论文库沉淀成可检索、可问答的知识图谱。
示例话术:
我们可以把论文、白皮书、技术报告批量转换成结构化知识图谱,再通过语义搜索和问答快速定位“某个方法解决什么问题、用了哪些数据集、和哪些方法有关”。
4.2 金融财报和公告分析
适合对象:
- 证券研究
- 投资分析
- 风控团队
- 企业财务分析团队
可解决问题:
- 财报、公告、电话会纪要信息密集。
- 风险因素、业务板块、核心指标、管理层表述分散在长文档中。
- 希望从“文档阅读”升级为“实体关系和风险知识库”。
示例命令:
he parse earnings.md -t finance/earnings_graph -o ./finance_kb/
he search ./finance_kb/ "What are the key risk factors?"售前价值:
- 更快搭建财务事件知识图谱。
- 支持跨报告搜索。
- 可用于投研助手、风险审查、公告摘要、行业知识沉淀。
4.3 法务合同和合规审查
适合对象:
- 法务团队
- 合规部门
- 律所
- 合同管理系统厂商
可解决问题:
- 合同条款多,义务、主体、条件、违约责任关系复杂。
- 传统关键词检索很难识别“谁对谁承担什么义务,在什么条件下触发”。
- 需要把合同文本转成结构化审查对象。
售前价值:
- 合同主体、条款、义务、期限、风险点抽取。
- 合规文档和法规条款关系梳理。
- 为合同问答、风险提示、条款比对提供知识结构基础。
4.4 医疗、中医药和专业知识库
适合对象:
- 医疗信息化厂商
- 医学知识库团队
- 中医药研究机构
- 医学内容运营团队
可解决问题:
- 医学文档中实体关系复杂,包括疾病、症状、药物、治疗、禁忌、指南证据。
- 中医文档中有药材、方剂、症候、治法等专门关系。
售前提醒:
医疗场景必须强调“辅助分析”和“人工审核”,不能作为自动诊断或自动处方依据。Hyper-Extract 适合做知识整理和检索增强,不适合直接承担高风险医疗决策。
4.5 工业文档和设备知识库
适合对象:
- 制造企业
- 工业软件厂商
- 设备运维团队
- 质量和安全管理团队
可解决问题:
- 设备手册、故障报告、维修记录、SOP 很多。
- 故障现象、原因、处理步骤、部件、工况之间存在复杂关系。
- 一线人员需要快速查询和问答。
售前价值:
- 把运维文档抽成故障知识图谱。
- 支持“症状 -> 原因 -> 处理方案”的关系查询。
- 结合 Agent 或客服系统做维修助手。
4.6 企业知识管理和 Obsidian/Markdown 知识库
适合对象:
- 咨询公司
- 售前团队
- 研发知识管理团队
- 个人知识库重度用户
可解决问题:
- 文档很多,但知识之间缺少连接。
- Markdown/Obsidian 中人工建立双链成本高。
- 希望将文档自动拆成节点、关系和索引。
售前价值:
- 通过
he export obsidian输出可读、可编辑、可迁移的 Markdown。 - 可把客户资料、行业报告、产品文档转为 Obsidian 双链知识库。
- 不绑定特定商业平台,便于客户接受。
4.7 Agent 知识工具接入
适合对象:
- 正在做企业 Agent 平台的团队
- AI 助手/知识助手开发团队
- 使用 Claude Desktop、Cursor、Codex、MCP 的技术团队
可解决问题:
- Agent 需要稳定、结构化、可查询的外部知识。
- 直接让 Agent 读原始文档成本高、可靠性差。
- 需要把已有知识对象作为工具暴露给 Agent。
售前价值:
- 通过 MCP 把知识对象开放成
search、ask、export_obsidian等工具。 - 比“Agent 每次从头读文档”更稳定。
- 适合作为企业 Agent 的知识底座 PoC。
5. 不太适合的场景
| 场景 | 原因 |
|---|---|
| 只需要全文搜索 | Elasticsearch、向量数据库或普通 RAG 可能更简单 |
| 只做固定字段 ETL | 传统规则、OCR 表格抽取、数据管道更确定 |
| 高风险自动决策 | LLM 抽取存在错误和幻觉,必须人工复核 |
| 超大规模生产图数据库 | Hyper-Extract 更像抽取与知识对象框架,不是 Neo4j/JanusGraph 级图数据库 |
| 对确定性要求极高 | LLM 输出受模型、提示词和上下文影响 |
| 模型不支持结构化输出 | 项目强依赖结构化 JSON/schema 输出能力 |
| 客户完全不接受 LLM 调用外部 API | 可用本地 vLLM,但需要 GPU 和部署能力 |
6. 核心能力清单
| 能力 | 说明 | 售前价值 |
|---|---|---|
| 强类型知识抽取 | 把文本抽成 Pydantic/Auto-Type 对象 | 从“总结”升级到“知识资产” |
| 8 类知识结构 | Model/List/Set/Graph/Hypergraph/Temporal/Spatial/SpatioTemporal | 能覆盖更多复杂业务关系 |
| 模板系统 | 80+ YAML 模板,覆盖金融、法律、医疗、中医、工业、通用 | PoC 启动快,可定制 |
| 多抽取方法 | 支持 GraphRAG、LightRAG、Hyper-RAG、KG-Gen 等思路 | 可根据场景选择不同抽取策略 |
| 增量演化 | he feed 持续喂入新文档 | 知识库可以持续更新 |
| 语义搜索 | he search | 快速从结构化知识中找答案 |
| 知识问答 | he talk 或 MCP ask | 适合做企业知识助手 |
| 可视化 | he show | 演示效果直观,适合 PoC 汇报 |
| Obsidian 导出 | he export obsidian | 输出 Markdown 和双链,降低客户迁移顾虑 |
| MCP Server | he-mcp | 便于接入 Agent 工具生态 |
| 云模型与本地模型 | OpenAI、Anthropic、阿里云百炼、本地 vLLM | 能覆盖公有云和私有化诉求 |
7. 架构和工作方式
官方架构可以概括为:
7.1 文本处理
文档会被切分成 chunk。官方架构文档提到默认大小约 2048 字符,overlap 约 256。大文档会拆成多个块并行处理。
售前提醒:
- 长文档可以处理,但成本和耗时会上升。
- 官方文档提示超过 50KB 的文档可能产生 25+ chunks,并显著变慢。
- 大规模生产使用时,需要规划并发、缓存、模型成本和失败重试。
7.2 LLM 抽取
系统根据模板生成提示词,调用 LLM 的结构化输出能力,再解析为 Pydantic/Auto-Type 结构。
这意味着模型能力很关键:
- 支持
json_schema的模型更适合。 - 输出不稳定的模型会影响抽取质量。
- 本地模型需要选择适配结构化输出的版本和服务方式。
7.3 合并与去重
多 chunk 抽取后,系统需要合并实体、关系和字段:
- 实体去重
- 关系合并
- 冲突处理
- 索引构建
这是项目的关键价值之一,因为真实文档里同一实体常常在不同段落中反复出现。
7.4 操作层
抽取完成后,可以做:
search:语义搜索chat/talk:围绕知识对象问答show:图谱可视化dump/load:保存和加载export obsidian:导出知识库
8. 怎么用
8.1 CLI 安装
官方推荐使用 uv:
uv tool install hyperextract
he --version也可以使用 pipx:
pipx install hyperextract
he --version8.2 初始化配置
he config init -k YOUR_OPENAI_API_KEY配置默认保存在:
~/.he/config.toml8.3 中文文档快速示例
he parse examples/zh/sushi.md -t general/biography_graph -o ./output/ -l zh
he search ./output/ "苏轼有哪些重要的作品?"
he show ./output/
he export obsidian ./output/ -o ./vault/8.4 英文论文/技术文档示例
he parse paper.pdf -t general/academic_graph -o ./paper_kb/ -l en
he search ./paper_kb/ "What are the key methods and datasets?"
he show ./paper_kb/8.5 财报分析示例
he parse earnings.md -t finance/earnings_graph -o ./finance_kb/ -l en
he search ./finance_kb/ "What are the key risk factors?"
he talk ./finance_kb/ -i8.6 增量更新
he feed ./finance_kb/ new_earnings_report.md
he build-index ./finance_kb/ -f适合持续加入新公告、新报告、新合同、新案例。
8.7 Python API
uv pip install hyperextractfrom hyperextract import Template
ka = Template.create("general/biography_graph")
with open("examples/en/tesla.md") as f:
result = ka.parse(f.read())
result.show()Python API 适合嵌入客户已有系统,例如文档平台、知识库后台、数据处理 pipeline 或内部 Agent 平台。
8.8 MCP Server
安装:
pip install 'hyperextract[mcp]'启动:
he-mcp或:
python -m hyperextract.mcp_server可以接入支持 MCP 的客户端,把 Hyper-Extract 生成的知识对象作为工具给 Agent 使用。官方强调 MCP Server 是只读与导出型能力,不会创建、修改或删除知识对象。
8.9 本地模型部署
官方文档中提到可用本地 vLLM 部署,例如:
- LLM:Qwen3.5-9B GPTQ-Marlin
- Embedding:BAAI/bge-m3
售前上可以把它作为“私有化部署可行路径”来讲,但需要注意:
- 需要 GPU 资源。
- 需要客户具备本地模型服务运维能力。
- 官方建议本地 vLLM 使用 non-thinking 模型或关闭 thinking,因为 thinking tags 可能干扰受约束 JSON 输出。
9. 支持的模型和 Provider
官方文档列出的典型支持情况:
| Provider | 模型 | 说明 |
|---|---|---|
| OpenAI | gpt-4o、gpt-4o-mini、gpt-5 | 原生 json_schema,适合结构化输出 |
| Anthropic | Claude Opus/Sonnet/Haiku 系列 | 可做 LLM,但没有 embedding API,需要搭配其他 embedding |
| 阿里云百炼 | qwen-plus、qwen-turbo、deepseek-r1 等 | 面向国内客户较友好 |
| 本地 vLLM | Qwen3.5-9B GPTQ-Marlin | 适合私有化或数据不出域 |
| Embedding | OpenAI text-embedding-3-small、百炼 text-embedding-v4、本地 bge-m3 | 用于语义搜索和索引 |
售前建议:
- 如果客户允许云 API,PoC 首选稳定支持结构化输出的云模型。
- 如果客户关注数据安全,准备本地 vLLM 方案,但要单独评估 GPU、吞吐、延迟和抽取质量。
- 如果客户在国内,阿里云百炼是更容易沟通的选项之一。
10. 售前怎么讲
10.1 面向业务方的话术
可以这样讲:
Hyper-Extract 可以把大量非结构化文档转成可查询、可关联、可持续更新的知识资产。它不只是总结文档,而是把文档中的人、组织、事件、指标、条款、时间、地点等关键对象抽取出来,并建立关系,方便后续搜索、问答、可视化和知识库沉淀。
业务价值:
- 降低人工阅读长文档成本。
- 提升跨文档检索和知识发现效率。
- 把专家经验和历史资料沉淀为结构化知识。
- 为企业知识助手、投研助手、合同助手、运维助手提供基础数据。
10.2 面向技术方的话术
可以这样讲:
Hyper-Extract 是一个以 Pydantic/Auto-Type 为核心的 LLM 知识抽取框架。它通过模板定义目标 schema,调用支持结构化输出的 LLM 进行抽取,然后做 chunk 级合并、去重、索引构建,并提供 CLI、Python API、Obsidian 导出和 MCP Server。
技术价值:
- 类型化输出,便于进入下游系统。
- 支持多种复杂图结构,不局限于普通知识图谱。
- 模板可扩展,适合做领域化定制。
- 支持云模型和本地模型两条路线。
- 可与 Agent/MCP 生态集成。
10.3 面向管理层的话术
可以这样讲:
它可以作为企业知识资产化的快速试验工具。前期用少量文档和模板快速验证“文档能否变成结构化知识”,中期接入知识问答和可视化,后期再决定是否和企业知识库、图数据库、搜索平台、Agent 平台打通。
管理价值:
- PoC 成本低。
- 演示效果直观。
- 可逐步扩展,不需要一开始建设大型知识图谱平台。
- 输出格式开放,降低技术锁定风险。
11. 推荐 PoC 方案
PoC 1:财报/公告知识抽取
目标客户:
- 投研团队
- 金融信息服务商
- 企业战略/财务团队
输入材料:
- 3-5 份公司年报
- 3-5 份公告
- 1-2 份电话会纪要
验证点:
- 是否能抽取公司、业务板块、财务指标、风险因素、管理层表述。
- 是否能跨文档搜索“某公司近几期的主要风险变化”。
- 是否能用图谱展示公司、业务、指标之间的关系。
演示命令:
he parse annual_report.md -t finance/earnings_graph -o ./finance_kb/ -l zh
he feed ./finance_kb/ announcement.md
he search ./finance_kb/ "这家公司当前最主要的经营风险是什么?"
he show ./finance_kb/PoC 2:合同义务和风险关系抽取
目标客户:
- 法务部门
- 合同管理系统厂商
- 合规团队
输入材料:
- 5-10 份合同样本
- 一份客户自定义风险清单
验证点:
- 是否能识别合同主体、义务、期限、条件、违约责任。
- 是否能把条款之间的依赖关系抽取出来。
- 是否能回答“甲方有哪些付款义务”“哪些条款存在高风险”。
输出形式:
- 合同知识图谱
- 风险点清单
- Obsidian/Markdown 知识库
- 后续可接入合同助手
PoC 3:科研论文知识图谱
目标客户:
- 科研团队
- 研究院
- 技术战略团队
输入材料:
- 某一主题下的 10 篇论文
验证点:
- 抽取作者、机构、任务、方法、数据集、指标、结论。
- 搜索“哪些方法使用了同一个数据集”。
- 可视化技术路线之间的关系。
演示命令:
he parse paper.pdf -t general/academic_graph -o ./paper_kb/ -l en
he feed ./paper_kb/ paper2.pdf
he search ./paper_kb/ "Which methods are related to retrieval augmented generation?"
he export obsidian ./paper_kb/ -o ./vault/PoC 4:企业内部知识库 + Obsidian/MCP
目标客户:
- 咨询公司
- 售前团队
- 企业知识管理团队
- Agent 平台团队
输入材料:
- 产品文档
- FAQ
- 解决方案材料
- 客户案例
验证点:
- 能否抽取产品、能力、行业、客户痛点、解决方案、案例之间的关系。
- 能否导出 Obsidian 双链知识库。
- 能否通过 MCP 给 Agent 查询。
演示路径:
he parse solution_docs.md -t general/knowledge_graph -o ./solution_kb/ -l zh
he export obsidian ./solution_kb/ -o ./vault/
he-mcp12. 与同类工具的差异
项目 README 中对比了 GraphRAG、LightRAG、KG-Gen、ATOM、Hyper-Extract 等工具。Hyper-Extract 官方强调自己的差异主要在:
| 维度 | Hyper-Extract 的特点 |
|---|---|
| 知识结构 | 不止普通 Knowledge Graph,还支持 Temporal、Spatial、Hypergraph、Spatio-Temporal |
| 领域模板 | 内置 80+ 模板,覆盖多个行业 |
| 使用入口 | CLI 友好,适合快速 PoC |
| 知识演化 | 支持 feed 增量更新 |
| 知识管理 | 支持 Obsidian 导出 |
| Agent 集成 | 支持 MCP Server |
| 本地化 | 支持本地 vLLM 和本地 embedding |
售前上不要把它讲成“替代所有 RAG/知识图谱平台”,更合适的定位是:
一个能快速把文档变成结构化知识对象的抽取层和 PoC 工具,可以与现有向量库、图数据库、知识库、Agent 平台结合。
13. 风险和注意事项
13.1 项目仍处 Alpha 阶段
pyproject.toml 中标注为 Alpha。虽然 GitHub 热度不错,但从生产系统角度看,需要关注:
- API 是否稳定
- 模板质量是否稳定
- 大规模文档处理是否成熟
- 错误处理和日志是否满足企业要求
- 社区维护节奏是否持续
13.2 LLM 抽取不是百分百准确
可能出现:
- 实体漏抽
- 关系误判
- 日期/数值错误
- 合并去重错误
- 模型幻觉
所以适合“辅助分析、知识整理、人工复核”,不适合无审核地进入高风险业务决策。
13.3 强依赖结构化输出能力
如果模型对 JSON schema 支持不好,抽取稳定性会下降。官方 Provider 文档也区分了 json_schema 和 json_object 能力。
售前建议:
- PoC 首选官方推荐模型。
- 本地模型要做结构化输出能力测试。
- 对关键字段设置人工抽样评估。
13.4 成本和延迟需要评估
长文档会切成多个 chunk,每个 chunk 都可能调用 LLM。需要评估:
- token 成本
- 并发能力
- 失败重试
- 向量索引成本
- 文档更新频率
13.5 Obsidian 导出不是企业权限系统
Obsidian 导出很适合知识管理和演示,但它不是权限管理、审计、版本审批、数据治理平台。企业生产落地时,仍需结合文档管理系统、知识库平台或权限系统。
13.6 它不是完整图数据库
Hyper-Extract 可以生成和展示图谱,但不要把它等同于 Neo4j、JanusGraph、NebulaGraph 这类图数据库。更准确的定位是“图谱抽取和知识对象生成层”。
14. 常见客户问题
Q1:它和普通 RAG 有什么不同?
普通 RAG 主要是切块、向量检索、回答。Hyper-Extract 更强调先把文档抽成结构化知识,例如实体、关系、事件、时间、地点、超边,然后再搜索、问答和导出。它更适合需要关系理解和知识沉淀的场景。
Q2:它能私有化部署吗?
可以走本地 vLLM + 本地 embedding 的路线。官方文档中提到 Qwen3.5-9B GPTQ-Marlin 和 bge-m3 的组合。不过私有化需要 GPU、模型服务、性能调优和抽取质量评估。
Q3:它能处理中文吗?
可以。官方有中文文档、中文示例和中文图谱展示图,CLI 中也支持 -l zh。
Q4:它能直接接企业知识库吗?
可以通过 Python API、CLI 输出、JSON/YAML、Obsidian Markdown、MCP 等方式集成。但如果要接企业权限、审计、审批、搜索平台,需要做二次开发。
Q5:适合直接上生产吗?
不建议直接承诺。项目当前标注 Alpha,适合先做 PoC、内部工具、知识抽取试验,再根据稳定性、准确率、吞吐和维护能力决定是否生产化。
Q6:它支持 Claude 吗?
支持 Anthropic Claude 作为 LLM,但 Claude 没有 embedding API,需要搭配 OpenAI-compatible embedding 或其他 embedding provider。
Q7:它能导入 Obsidian 吗?
可以。he export obsidian 会把图谱类知识对象导出成 Markdown 双链笔记,每个节点一篇笔记,并生成索引页。
15. 售前评分
| 维度 | 评分 | 说明 |
|---|---|---|
| 演示吸引力 | 4.5/5 | 图谱、Obsidian、MCP 都很容易演示 |
| PoC 启动速度 | 4/5 | CLI + 模板降低启动成本 |
| 企业落地成熟度 | 3/5 | Alpha 阶段,需要二次验证 |
| 场景覆盖度 | 4.5/5 | 金融、法务、医疗、工业、科研、知识管理均可讲 |
| 私有化友好度 | 3.5/5 | 支持本地 vLLM,但运维成本存在 |
| 差异化 | 4/5 | 多 Auto-Type 和 Obsidian/MCP 是亮点 |
16. 我的判断
Hyper-Extract 是一个很适合售前拿来做“文档知识抽取 PoC”的项目。它的最大亮点不是单点算法,而是把几个售前容易讲清楚的能力组合到了一起:
- 文档抽取
- 多种知识结构
- 模板化领域适配
- 可视化
- 语义搜索和问答
- Obsidian 导出
- MCP 接入 Agent
- 云模型/本地模型两条路线
对于客户,如果只是想做一个普通文档问答机器人,Hyper-Extract 可能不是最简单路线;但如果客户关心“文档里的关系、事件、实体、指标、条款如何沉淀成知识资产”,它就非常值得作为 PoC 工具。
最推荐的售前切入方式:
- 先选择一个客户熟悉的长文档场景,例如财报、合同、论文、设备手册。
- 用内置模板跑出知识图谱。
- 用
he show展示关系图。 - 用
he search或he talk做问答。 - 用
he export obsidian导出成双链知识库。 - 如果客户有 Agent 平台,再演示 MCP 查询。
这样能从“文档很多、读不完”自然过渡到“结构化知识资产”和“Agent 可用知识工具”,销售叙事比较顺。